autofz
本文最后更新于:8 个月前
Fuzz论文翻译autofz: https://www.usenix.org/system/files/usenixsecurity23-fu-yu-fu.pdf
ChaGPT的总结
论文简要 :
- 本文提出了一种自动化的元模糊测试器(autofz),通过动态组合模糊测试器以最大化现有模糊测试器的效果,解决了选择适合复杂实际程序的模糊测试器的难题,并在实验中展示了其优越性能。
背景信息:
- 论文背景: 近年来,模糊测试作为一种自动化的软件漏洞检测方法变得越来越受欢迎。然而,由于模糊测试器的多样性,选择适合复杂实际程序的模糊测试器变得困难,这被称为选择负担。为了解决这个问题,本文提出了一种自动化的元模糊测试器(autofz),通过动态组合模糊测试器以最大化现有模糊测试器的效果。
- 过去方案: 过去的研究努力通过创建一组标准基准来比较和对比模糊测试器的性能,但结果往往是次优的,最佳性能的模糊测试器平均而言并不能保证对用户感兴趣的目标的最佳结果。
- 论文的Motivation: 为了解决选择负担问题,本文提出了autofz,一个自动化的元模糊测试器,通过动态组合模糊测试器以最大化现有模糊测试器的效果。autofz通过监控模糊测试器的运行时进展,并对每个模糊测试器的资源分配(例如CPU时间)进行细粒度调整,从而在运行时以细粒度的方式推断出适合活动工作负载的模糊测试器集合。
方法:
a. 理论背景:
- 本文提出了一种自动化的元模糊器autofz,它在运行时动态地组合多个模糊器以最大化它们的性能。用户可以将所有可用的模糊器输入到autofz中,而不是手动选择一个模糊器,autofz会根据它们的运行进度调整每个模糊器的资源分配。评估结果显示,autofz在覆盖率和漏洞检测方面优于单个模糊器和协作模糊化方法。
b. 技术路线:
- autofz利用基线模糊器的运行时进展(称为趋势)来动态部署和调整模糊器。它将执行分为两个阶段:准备阶段和焦点阶段。在准备阶段,autofz捕获目标二进制文件的运行趋势,并部署具有强趋势的模糊器。在焦点阶段,autofz根据捕获的趋势和指导信息选择模糊器,还动态调整资源分配以最大化性能。
结果:
a. 详细的实验设置:
- 本文在Ubuntu 20.04上使用AMD Ryzen 9 3900处理器和32GB内存进行实验。使用Docker容器为与CUPID和ENFUZZ进行比较分配多个CPU核心。对于与单个模糊器进行比较的评估,使用一个CPU核心和无内存限制的容器。评估中使用的基线模糊器包括AFL,AFLFast,MOpt,FairFuzz,LearnAFL,QSYM,Angora,Redqueen,Radamsa,LAF-INTEL和libFuzzer。将autofz集成到UNIFUZZ和FTS中,以评估其在各种实际程序上的性能。使用基准提供的默认种子。
b. 详细的实验结果:
- autofz的评估结果显示,它在覆盖率和漏洞检测方面始终优于单个模糊器。在12个基准测试中,autofz比单个模糊器在11个基准测试中表现更好,在20个基准测试中击败了协作模糊化方法。平均而言,autofz比单个模糊器发现了152%更多的漏洞,比协作模糊化方法发现了415%更多的漏洞。此外,通过Critical Difference(CD)图表的比较,可以证明autofz在各个目标上的性能都优于单个模糊器。Mann-Whitney U检验也证实了autofz与大多数单个模糊器在统计上的差异。此外,对三个参数(Tprep,Tfocus和θinit)的不同配置进行的评估表明,不同的配置对性能没有明显的影响,说明autofz在初始配置方面表现良好。
论文翻译
autofz的运行原理
关键的思路是监控fuzzer的运行进度,即所谓的趋势。对每个fuzzer的资源分配(CPU时间)进行细粒度调整。与现有的静态组 合一 组 模糊器或通过对 每个目标程序进行详尽预训练的 方法形成了鲜明对比。autofz 的目标是通过模 糊器的 动态组合,将选择问题完全自动化。当最终用户选择一组基准模 糊器时,autofz 会自动利用运行时信息设计出性能最 佳的模糊器。
将基线模糊 器的运行进度称为 趋势。具体来说,在整个执行过 程中,autofz 会根据趋势的变化切换模糊器并调整 资源,而不是坚持使用一组特定的模糊器。
autofz的整体架构
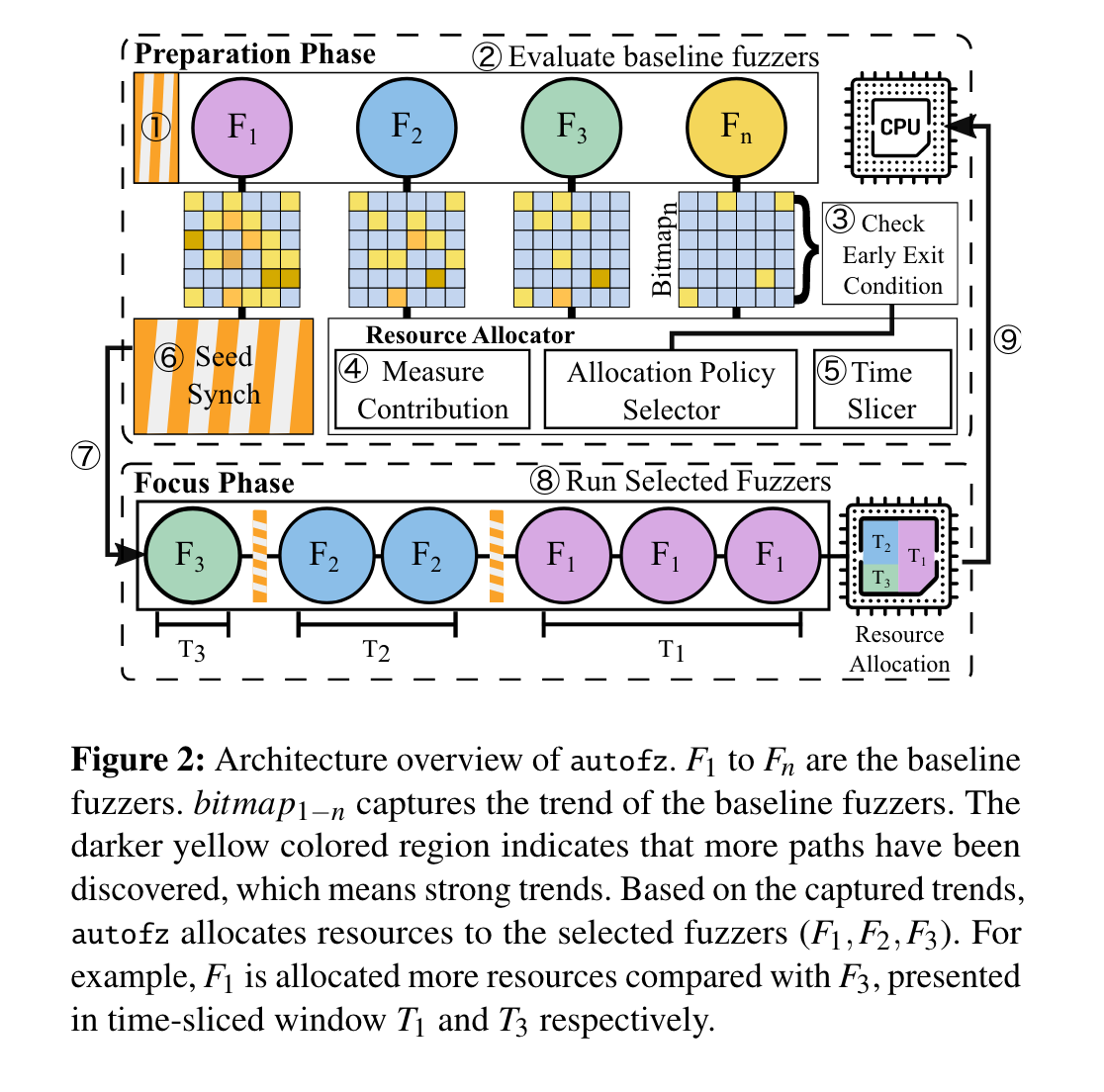
autofz的架构概览。 F1-Fn是基线模糊器,Bitmap-n反映可基线模糊器的趋势,黄色区域越深,表示 发现的路径越多,也就是趋势越强。根据捕获的趋势,autofz 将资源分配给选定的模糊器(F1 、F2 、F3)。例如 ,与 F3 相比,F1 被分配了更多资源,分别出现在时间片窗口 T1 和 T3 中。
autofz 将其执行分为两个不同阶段,即准备阶段 和重点阶段
准备阶段
准备阶段 捕获目标二进制文件的运行趋势,并部署能说明强 烈趋势的模糊器。根据捕获的趋势和指导信息,重点阶段尝试使用所选模糊器实现最佳性能。autofz 利用指导信息进行动态资源调整,使其既能享受单个模糊器的最佳性能,又能享受不同模糊器组合的最佳性能。
准备阶段至关重要,因为其结果影响后续foucs phase的决策。
foucs phase
根据准备阶段的信息,选择性能最佳的模糊器对目标的二进制文件进行fuzz
优势
- 每个工作负载的动态模糊器组成
在整个模糊测试过程中,autofz 不需要使用一组静态模糊器。从本质上讲,除了持续 选择性能良好的模糊器外,autofz 还能给那些未被 选中但后来发现适合特定工作负载的模糊器第二次 机会。 - 自动和非侵入方法
可自动为任何给定的目标选择最合适的模糊器,降低了使用者的门槛。 - 高效的资源调度算法
可确保单个模糊器的性 能,并将计算资源高效地分配给选定的模糊器,有助于利用单个fuzzer的最大优势,同时最大限度地发挥多个不同fuzzer的协作效果。此外,autofz 首先强调资源调度是影响协作效率的另一个重要因素。
相关工作
Fuzzing benchmark
模糊测试基准
使用模糊测试套件 Fuzzer Test Suite,FTS,以及UNIFuzz
Collaborative fuzzing
协作式模糊测试试图通过协调多个 不同类型的模糊器与种子同步(见下文)来提高模 糊测试活动的性能。这样做能提高代码覆盖率

Seed synchronization
种子同步,将其他fuzzer的有趣的种子,同步到无法向下执行的fuzzer中。
autofz概述
autofz 旨在解决 选择问题。其关键思路是根据运行时 的模糊器评估结果,为每个工作负载动态部署不同的模 糊器集。为此,autofz 由两个重要部分组成:准备阶段和聚焦阶段。
准备阶段
准备阶段在运行时定期监控单个模糊器的进度(称为趋势),并 将其作为选择下一组模糊器的决策反馈。由于工作量在 模糊处理过程中会发生变化,因此准备阶段有助于 autofz 适应变化的趋势。有了准备阶段,重 点阶段就能确定所选模糊器的优先级,并为任何目标二 进制文件取得最佳结果。
autofz会在准备阶段的每一轮同步所有fuzzer的种子。为所有的fuzzer分配相同数量的资源,每个模糊器在很短的时间 间隔内轮流运行,直到遇到退出条件。
autofz 利用基线 模糊器的评估结果 AFL 位图来衡量所有模糊器的趋势。
考虑到趋势,autofz 会选择基线模糊器的一个子集 以及资源分配元数据,决定每个模糊器在当前工作量下的优先级 (4)。
在过渡到FOUCS阶段之前进行种子同步 ( 6 , 7 ) 可以让所选模糊器共享准 备阶段产生的独特测试用例FOUCS阶段
按照资源分配元数据逐一运行选 定的模糊器。每个模糊器都有一个特定的 CPU 时 间窗口来取得进展 ( 8 )。在此阶段目标是实现最高性能,而不是公平比较。
因此,在一个fuzzer执行后,我们会同步种子,让其余fuzzer探索其他fuzzer未发现的路径。当分配的资源全部耗尽时, 它就会回到准备阶段并测量趋势 ( 9 )。这两个阶段 之间的执行流一直持续到模糊执行结束(例如 24 小时)。
Preparation Phase

Preparation phase的目标是适当地选择那些能说明强烈趋势的 模糊器,以帮助Foucs phase实现最高性能。
Dynamic time in preparation phase
为了适应不断变化的工作量并找到最合适的模糊器,准备阶段应评估所有基线模糊器, 直到可以捕捉到强烈的趋势。但是,如果准备阶段花费的时间过长,就会浪费宝贵的测量资源。虽然 autofz 也可以利用准备阶段的时间来取得进展,但它可以通过 更早、更长地优先选择模糊器来实现更好的性能。相反 ,如果准备时间太短,则很难捕捉模糊器的明确趋势。 这就会使 autofz 不恰当地优先处理一组次优模糊器, 贸然将宝贵的资源分配给它们。但是准备时间是未知的,autofz采用动态准备时间,采用的算法是AIMD(Additive-Increase/Multiplicative- Decrease)。TCP拥塞控制采用的算法。
Early exit and threshold
如果 autofz 能够更早地找到具有强烈趋势的模糊器,就可以将 剩余资源分配给重点阶段,为了避免减少准 备时间、过早做出决定的缺点,autofz 需要一个明 确的强趋势指标。
利用位图的 峰值差(diffpeak ),即表现最好和最差模糊器之间 的差值。检测到早期退出条件后,autofz 会立即进 入聚焦阶段。
提前退出所产生的剩余时间 将分配给聚焦阶段,这样它就能更早更长时间地执行所选模糊器。引入了一个阈值(以 θ 表示) ,如果峰值差大于 θ,则允许准备阶段提前退出。

Trend evaluation
在算法2中,利用位图操作来衡 量单个模糊器的趋势。为此,autofz 会测量每个模 糊器在准备阶段探索过的唯一路径。由于在准备阶 段之前进行了种子同步,因此每个模糊器位图中的 唯一条目都可以代表其自身的贡献。
将所有模 糊器在准备阶段探索过的共同路径显示为 b∩ (第 5行),从单个模糊器的位图中减去它,这样就可以 根据在准备阶段发现的唯一路径来衡量每个模糊器的贡 献。
Resource assignment
如果某些模糊器表现出色,就会暂时为它们 分配更多资源。Autofz 可以加速性能良好的模 糊器,而将其他模糊器降级。Autofz 引入了新颖的策 略,允许在选定的模糊器之间高效分配资源。由于资源 分配的多样性,autofz 可以同时利用单个模糊器和协作模糊。autofz 支持两种资源分配方式。
#💡??? 是不是可以在资源分配上做文章?
- prioritizes the best — 最佳优先级
优先考虑最好的模糊器,将所有资 源分配给排名最靠前的模糊器,只有当某个模糊器的性 能明显优于其他所有基线模糊器时,才会启用该策略。
算法2中 Exitearly作为这种情况的一种信号。当提前退出发生时,首先要找到发现最独特路径的 模糊器集合(max_ fuzzers)(第 8-13 行)。 - proportionally distribute resources based on the trends of each fuzzer — 根据每个模糊器的发展趋势按比例分配资源
这是很好理解的一种资源分配策略,能者多劳,获得资源就越多。
在这 种情况下,就会根据模糊器的贡献,按比例向它们 分配资源(第 16 行),从而实现协同模糊的优势。autofz可以在选定的模糊器之间分配资源。
Putting them all together
算法 1 所述,准备阶段的每一轮都需要 基线模糊器 (F)、它们的位图 (B)、为当前模糊器分配的时间预算 (C)、它们的位图 (D)、为当前模糊器分配的时间预算 (E)。 轮(Tprep ),以及检测早期退出事件的阈值(θ )cur 因此,准备阶段会返回 Exitearly ,表明是否发生提前退出, 并在发生提前退出时返回非零值的 Tremain 。此外,它还会返回 RA 资源分配元数据。属于 F 的每个模糊器轮流在很短的时间间隔(30 秒或 Tremain )内运行。在对 F 中的所有模糊器进行评估之后,准备阶段会检查峰值差是否大于 θcur ,并提前退出。如果条件满足,则运行模糊器。但是,如果差异仍低于 阈值 θcur ,则准备阶段会在另一个较短的时间间隔内运 行每个模糊器。准备阶段将重复这一过程,直到观察到 较大的覆盖率差异或耗尽预定的时间预算(Tprep )。
为每个模糊器分配较短的时间间隔不会显著提高autofz的性能。因为没fuzzer之间的切换与系统中进城切换一样,需要保存上下文,这也会浪费时间。这里限定的执行时间为30s。
对于多核,并行运行所有模糊器,并将其分配给不同的模 糊器。 平均分配 CPU 资源。RUN_FUZZERS_PARALLEL(F, T, c) 运 行所有模糊器 f∈F T 秒,每个模糊器分配 c 个 CPU 内 核。
Foucs Phase
算法4描述了autofz的foucs phase阶段如何利用同一轮准备生成的信息运行选定的fuzzer。模糊器(F)和资源分配元数据(RA)被传递到 Foucs Phase。因为每个模糊器的时间预算本轮允许消耗的资源是根据 RA 计算的,不会分配给在准备阶段未被选中的模糊器。
此外,Foucs Phase需要 T focus ,它每一轮都不同,取决于准备阶段在 这一轮中何时退出。请注意,当准备阶段提前退出时,剩余的时间预算将分配给重点阶段,使其能够更长时间地利用强趋势。Foucs Phase首先计算总的时间预算(第 3 行),然后根据以下条件对模糊器进行排序:
先运行性能良好的模糊器(第 4 行)。然后,计算基线模糊器的时间预算 (第 6 行),如果分配的预算不为零(第 7-8 行), 则运行模糊器。请注意,每执行一个模糊器,Foucs phase都会同步种子和位图(第 9 行),以累计所有选定模糊器的进度。
如果在准备阶段选择了多个模 糊器,种子同步将允许每个模糊器发现其他模糊器未探索过的独特路径。
对于多核版本,我们首先计算应分配多少个内核 c 给下列模糊器根据资源分配 RA 运行每个模糊器(第 11 行), 然后根据结果并行运行所有模糊器(第 12 行)。

Implementation
autofz 包含 6.2K 行 Python3 代码(4.8K 行用于主 框架,1.4K 行用于模糊器 API)。为了根据 资源分配情况限制所选模糊器的资源使用,使用了 cgroups ,它可以对进程进行分级管理,并限制每个组的资源使用。
cgroups(控制组)是Linux内核的一个功能,它允许进程被组织成分层的组,并为这些组分配资源。这种技术主要用于资源限制、优先级调整、资源计量和资源隔离。
AFL bitmap measuring coverage of fuzzers
在 autofz 中,每个 基线模糊器都使用其原始设计的模糊算法,不涉及任何实现变更。因此,在这两个阶段中,每个模糊器都可以 根据其内部指标和算法生成不同的有趣输入。不过,如第 4.1 节所述,autofz 需要重新获取所有基线模糊器的 AFL 位图,以便公平地比较趋势。具体来说,autofz 使用每个模糊器认为有趣的不同输入调用 AFL 仪表二 进制。每个模糊器都可以将有趣的输入作为文件保存在不同的目录中。因此,当新的模糊器集成到 autofz 时 , autofz 就 应 该 知 道 这 些 信 息 。 例 如 , Angora 将 “queue”、”crashes “和 “hangs “配置为有趣的输入目录 。因此,在准备阶段,一旦在指定目录中创建了新文件 ,autofz 就会调用带有新输入的 AFL 仪器目标,并测 量 Angora 的 AFL 位图覆盖范围。
API for integration
实现以下 python API 的任何单个模糊器都可以集成到 autofz 中。 1. Start / Stop 2. Scale up / down (for parallel mode).
启动每个模糊器需要不同的参数和文件目录。通过启动和停止 API,autofz 可以了解如何使用适当的参数启动和停止每个模糊器。 此外,每个模糊器都应实现 Scale Up 和 Down API,以 利用多核资源。例如,AFL 有主模式和从模式。因此, 用户需要实施 Scale Up API 来启动更多的从实例,而不 是主实例。
Multi-core support
autofz 能够利用多个内核。对于多核实现,我们同时 运行 在准备阶段和聚焦阶段,autofz 都会对模糊器进行实例 化。例如,如果我们有 N 个内核,autofz 会使用针对 模糊器 f 的 Scale Up API 实例化 ⌈N ×RA[ f ]⌉个进程。之 后 autofz 利用 cgroups 将分配给所生成模糊器实例的 CPU 资源总量精确限制为 N × RA[ f ]。
Evaluation
实验部分,作者用实验数据强调了autofz目前的优势,与其存在的巨大意义,建议直接看原文。
Discussion
- Autofz 利用 AFL 位图来比较运行时趋势,这有利于寻 求最大路径覆盖率的模糊器。虽然覆盖率是模糊处理中最常用、最明确的进度指标,但依赖单一指标可能会导致与使用覆盖率以外指标的各种模糊器进行不公平的比较 [16, 39, 46-48]。因此,除路径覆盖率外,支持多种指标可以 在资源分配方面实现公平性和更好的效率。例如,可以使用不同的指标来打破平局,尤其是在一种指标已经饱和的情况 下。
- 消除不良模糊器。在对特定目标进行模糊测试的整 个过程中,某个模糊器可能表现不佳(例如图 3 中 显示的对 exiv2 进行模糊测试的 Radamsa)。不过 ,在准备阶段,所有基线模糊器都会分配到相同数量的资源,以测量运行时趋势。如果能及时将性能较差的模糊器从基线中剔除,autofz 就能实现更高的资源利用率。
Conclusion
本文介绍了一种元模糊器 autofz,它可提供细粒度 和非侵入式模糊器协调。我们的评估结果表明,在没有任何先验知识的情况下自动组成模糊器是有效的。通过观察运行时模糊器的趋势并适当分配计算 资源,autofz 不仅战胜了单个模糊器,还战胜了最 先进的协同模糊方法。我们希望 autofz 能够 弥补 新模糊器的开发与有效部署之间的差距。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
