MYDB
本文最后更新于:1 年前
MYDB项目的总结
花了一周从头到尾看了整个项目,在此做个总结,真是太复杂了,实在佩服作者。如果有错误,请指正。
MYDB的每个部分的作用
TM 通过维护 XID 文件来维护事务的状态,并提供接口供其他模块来查询某个事务的状态。
DM 直接管理数据库 DB 文件和日志文件。DM 的主要职责有:
分页管理 DB 文件,并进行缓存;
管理日志文件,保证在发生错误时可以根据日志进行恢复;
抽象 DB 文件为 DataItem 供上层模块使用,并提供缓存。
VM 基于两段锁协议实现了调度序列的可串行化,并实现了 MVCC 以消除读写阻塞。同时实现了两种隔离级别。
IM 实现了基于 B+ 树的索引,BTW,目前 where 只支持已索引字段。
TBM 实现了对字段和表的管理。同时,解析 SQL 语句,并根据语句操作表。
服务端执行流程
1.创建对底层的tm模块
TransactionManagerImpl tm= TransactionManager.create("cun/tm");此时会创建一个tm.xid文件,所有的事务xid存放在此
2.基于tm创建dm模块
DataManager dm=DataManager.create("cun/dm",1 << 20,tm);DataManager创建过程中,会创建PageCache,Logger
PageCache pc = PageCache.create(path, mem);
Logger lg = Logger.create(path);
// 此时创建了dm.db和dm.log,分别存储数据库数据 和 日志记录
DataManagerImpl dm = new DataManagerImpl(pc, lg, tm);
dm.initPageOne();
//并对pageOne进行初始化3.创建VM模块,此处要tm,dm
VersionManager vm= VersionManager.newVersionManager(tm,dm);首先会初始化缓存框架中的信息,初始化成员变量,将SUPER_XID(0)加入到活跃事务列表
public VersionManagerImpl(TransactionManager tm, DataManager dm) {
super(0); // 调用父类AbstractCache的构造方法 初始maxResource
this.tm = tm;
this.dm = dm;
this.activeTransaction = new HashMap<>();
// 初始化 活跃事务列表,并将超级事务 就xid为0的
activeTransaction.put(TransactionManagerImpl.SUPER_XID, Transaction.newTransaction(TransactionManagerImpl.SUPER_XID, 0, null));
this.lock = new ReentrantLock();
this.lt = new LockTable();
}4.创建TM模块,此处基于VM,DM
TableManager tbm=TableManager.create("cun/",vm,dm);创建文件.tb用于存放表信息
public static TableManager create(String path, VersionManager vm, DataManager dm) {
Booter booter = Booter.create(path);
booter.update(Parser.long2Byte(0));
return new TableManagerImpl(vm, dm, booter);
}5.开启事务
BeginRes br=tbm.begin(new Begin());6.解析SQL语句
long xid=br.xid;
//建立一张新表
String ss="create table students " +
"name string,age int32 " +
"(index name age)";
byte b[]=ss.getBytes(StandardCharsets.UTF_8);
Object stat = Parser.Parse(b);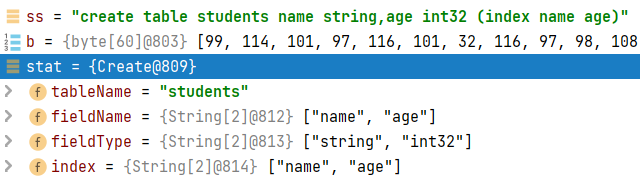
可以看到,解析后会返回一个Object对象,其包含了表名,字段名,字段类型以及索引
7.执行创建表的SQL语句
分为四种情况
开启一个事务sql语句为 begin
提交一个事务sql语句为 commit
回滚事务sql语句为abort
其他sql语句 CRUD
MYDB执行sql时,默认是开启事务的,即一条sql语句也是需要提交事务的,也开启手动即begin,保持多个操作的原子性
Object stat = Parser.Parse(sql);
if(Begin.class.isInstance(stat)) {
if(xid != 0) {
throw Error.NestedTransactionException;
}
BeginRes r = tbm.begin((Begin)stat);
xid = r.xid;
return r.result;
} else if(Commit.class.isInstance(stat)) {
if(xid == 0) {
throw Error.NoTransactionException;
}
byte[] res = tbm.commit(xid);
xid = 0;
return res;
} else if(Abort.class.isInstance(stat)) {
if(xid == 0) {
throw Error.NoTransactionException;
}
byte[] res = tbm.abort(xid);
xid = 0;
return res;
} else {
// execute2就是执行CRUD操作的sql
return execute2(stat);
}创建一张表
假设execute2此时执行的是下面的sql语句
// create table students name string,age int32 (index name age)
String ss="create table students " +
"name string,age int32 " +
"(index name age)";
byte b[]=ss.getBytes(StandardCharsets.UTF_8);
Object stat = Parser.Parse(b);
tbm.create(xid,(Create) stat);首先会到表的缓存查询是否存在该表名
也就是第一个if语句中的代码
public byte[] create(long xid, Create create) throws Exception {
lock.lock();
try {
// 此处代码
if(tableCache.containsKey(create.tableName)) {
throw Error.DuplicatedTableException;
}
Table table = Table.createTable(this, firstTableUid(), xid, create);
updateFirstTableUid(table.uid);
tableCache.put(create.tableName, table);
if(!xidTableCache.containsKey(xid)) {
xidTableCache.put(xid, new ArrayList<>());
}
xidTableCache.get(xid).add(table);
return ("create " + create.tableName).getBytes();
} finally {
lock.unlock();
}
}- 如果存在,说明表名重复,抛出异常
- 如果没有,则创建一张新表
public byte[] create(long xid, Create create) throws Exception {
lock.lock();
try {
if(tableCache.containsKey(create.tableName)) {
throw Error.DuplicatedTableException;
}
// 接下来解释的是这一行代码的执行过程
Table table = Table.createTable(this, firstTableUid(), xid, create);
updateFirstTableUid(table.uid);
tableCache.put(create.tableName, table);
if(!xidTableCache.containsKey(xid)) {
xidTableCache.put(xid, new ArrayList<>());
}
xidTableCache.get(xid).add(table);
return ("create " + create.tableName).getBytes();
} finally {
lock.unlock();
}
}接下来将进入最核心的代码块中Table table = Table.createTable(this, firstTableUid(), xid, create);
进入Table.createTable
// 创建一个新的Table对象,并根据传入的Create对象创建字段 nextUid = 0
Table tb = new Table(tbm, create.tableName, nextUid);
for(int i = 0; i < create.fieldName.length; i ++) {
String fieldName = create.fieldName[i];
String fieldType = create.fieldType[i];
boolean indexed = false;
for(int j = 0; j < create.index.length; j ++) {
if(fieldName.equals(create.index[j])) {
indexed = true;
break;
}
}
// 创建字段
tb.fields.add(Field.createField(tb, xid, fieldName, fieldType, indexed));
// 将新建的Field对象添加到Table对象的fields列表中
}

在for循环中取出表的所有字段信息和类型,并判断是否为索引类型,接着创建字段信息
进入Field.createField代码逻辑
typeCheck(fieldType);
Field f = new Field(tb, fieldName, fieldType, 0);
if(indexed) {
long index = BPlusTree.create(((TableManagerImpl)tb.tbm).dm);
BPlusTree bt = BPlusTree.load(index, ((TableManagerImpl)tb.tbm).dm);
f.index = index;
f.bt = bt;
}
f.persistSelf(xid);
return f;如果该字段是索引类型,将会为该索引创建B+树,以上参数信息如下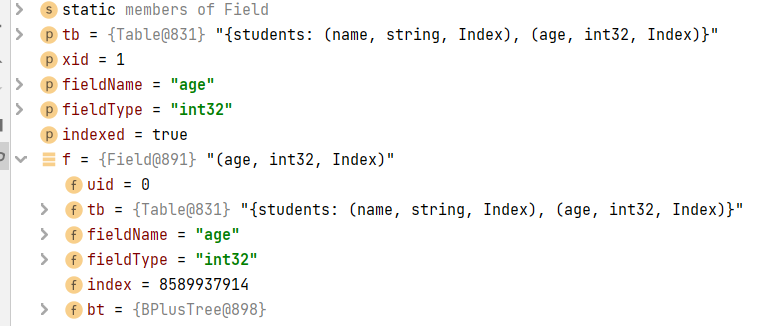
![]
persistSelf()
最后会执行persistSelf(),将字段数据写入磁盘
private void persistSelf(long xid) throws Exception {
byte[] nameRaw = Parser.string2Byte(fieldName);
byte[] typeRaw = Parser.string2Byte(fieldType);
byte[] indexRaw = Parser.long2Byte(index);
this.uid = ((TableManagerImpl)tb.tbm).vm.insert(xid, Bytes.concat(nameRaw, typeRaw, indexRaw));
}将字段名、类型以及索引值转换为byte类型,交给vm插入
进入((TableManagerImpl)tb.tbm).vm.insert逻辑
public long insert(long xid, byte[] data) throws Exception {
lock.lock();
Transaction t = activeTransaction.get(xid); //从活跃的事务列表中取出该事务
lock.unlock();
if(t.err != null) {
throw t.err;
}
// 将数据拼接成一个Entry
byte[] raw = Entry.wrapEntryRaw(xid, data);
// 插入DataItem的Data位置
return dm.insert(xid, raw);
}该段中raw的数据如下,就是在VM模块中介绍的Entry的存储结构
进入dm.insert()执行流程
byte[] raw = DataItem.wrapDataItemRaw(data);
if(raw.length > PageX.MAX_FREE_SPACE) {
throw Error.DataTooLargeException;
}
使用PageIndex选择合适的页面进行存储
PageInfo pi = null;
for(int i = 0; i < 5; i ++) {
pi = pIndex.select(raw.length);
if (pi != null) {
break;
} else {
int newPgno = pc.newPage(PageX.initRaw());
pIndex.add(newPgno, PageX.MAX_FREE_SPACE);
}
}取出page,插入insertLog,用于恢复时使用
pg = pc.getPage(pi.pgno);
byte[] log = Recover.insertLog(xid, pg, raw); // 解析出log返回,log的格式如下图
logger.log(log); // 向.log文件中写入log,并更行日志文件的校验和,用于数据恢复
short offset = PageX.insert(pg, raw); // .db文件中写入真正的数据
pg.release();
return Types.addressToUid(pi.pgno, offset);
finally {
// 将取出的pg重新插入pIndex
if(pg != null) {
pIndex.add(pi.pgno, PageX.getFreeSpace(pg));
} else {
pIndex.add(pi.pgno, freeSpace);
}
}==以上代码都在dm.insert()中==
log变量的存储结构如下所示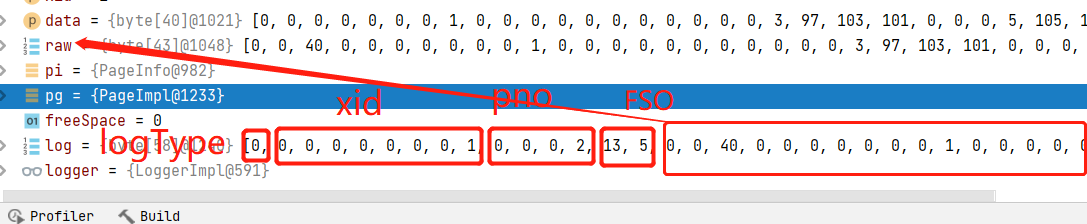
最后返回插入位置的偏移量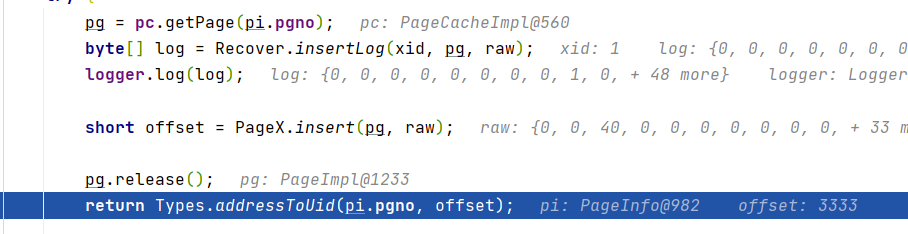
PageX.inset()的代码逻辑
public static short insert(Page pg, byte[] raw) {
pg.setDirty(true); // 此时该位置数据更新 所以为脏数据
short offset = getFSO(pg.getData()); // 获取空闲位置的偏移 在之后插入数据
System.arraycopy(raw, 0, pg.getData(), offset, raw.length); // 将数据拷贝到指定的内存地址
setFSO(pg.getData(), (short)(offset + raw.length)); // 更新FSO
return offset;
}完成上面的一系列操作后,sql的执行过程已经持久化到磁盘中。
回到tbm.create(xid,(Create) stat);`中
updateFirstTableUid(table.uid); // 更新.tb文件
tableCache.put(create.tableName, table);
if(!xidTableCache.containsKey(xid)) {
xidTableCache.put(xid, new ArrayList<>());
}
xidTableCache.get(xid).add(table);
return ("create " + create.tableName).getBytes();updateFirstTableUid()用于将新增表的uid更新到.tb文件中,该函数会调用Booter.update()函数,该函数在更新.tb文件时,用创建一个新文件其后缀为.bt_tmp
之后,将新数据写入该文件,再将.bt文件中的内容拷贝到临时文件.bt_tmp中,准备好全部数据后,会用.bt_tmp将原来的.bt文件覆盖。如此更新数据,是为了保证更新数据的原子性。
public void update(byte[] data) {
File tmp = new File(path + BOOTER_TMP_SUFFIX);
try {
tmp.createNewFile();
} catch (Exception e) {
Panic.panic(e);
}
if(!tmp.canRead() || !tmp.canWrite()) {
Panic.panic(Error.FileCannotRWException);
}
try(FileOutputStream out = new FileOutputStream(tmp)) {
out.write(data);
out.flush();
} catch(IOException e) {
Panic.panic(e);
}
try {
// 覆盖原文件
Files.move(tmp.toPath(), new File(path+BOOTER_SUFFIX).toPath(), StandardCopyOption.REPLACE_EXISTING);
} catch(IOException e) {
Panic.panic(e);
}
// 返回新的File对象
file = new File(path+BOOTER_SUFFIX);
if(!file.canRead() || !file.canWrite()) {
Panic.panic(Error.FileCannotRWException);
}
}接着继续回到tbm.create(xid,(Create) stat)中,后面的代码相对简单。
tableCache.put(create.tableName, table); // 将创建好的表名放进 表缓存tableCache,方便下次创建表时,进行表名重复的检查
// xidTableCache 存放的是事务xid创建的table集合
if(!xidTableCache.containsKey(xid)) { // 如果该事务xid 不在xidTableCache中,则将其加入
xidTableCache.put(xid, new ArrayList<>());
}
// 将创建的表名加入
xidTableCache.get(xid).add(table);
return ("create " + create.tableName).getBytes(); // 返回此次sql语句执行的结果8.执行插入的SQL语句
ss="insert into students values xiaohong 18";
b=ss.getBytes(StandardCharsets.UTF_8);
stat = Parser.Parse(b);
tbm.insert(xid,(Insert) stat);解析出的sql语句
tbm.insert()中的代码
@Override
public byte[] insert(long xid, Insert insert) throws Exception {
lock.lock();
Table table = tableCache.get(insert.tableName);
lock.unlock();
if(table == null) {
throw Error.TableNotFoundException;
}
table.insert(xid, insert);
return "insert".getBytes();
}首先检查表名是否存在,不在则抛出TableNotFoundException异常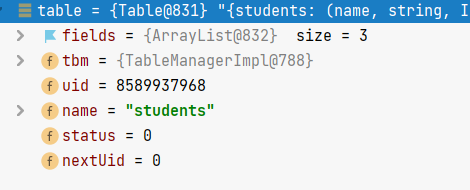
如果存在,则进入table.insert(xid, insert),代码如下
public void insert(long xid, Insert insert) throws Exception {
Map<String, Object> entry = string2Entry(insert.values);
byte[] raw = entry2Raw(entry);
long uid = ((TableManagerImpl)tbm).vm.insert(xid, raw);
for (Field field : fields) {
if(field.isIndexed()) {
field.insert(entry.get(field.fieldName), uid);
}
}
}首先将SQL语句转换成一条Entry
接着进入long uid = ((TableManagerImpl)tbm).vm.insert(xid, raw);
@Override
public long insert(long xid, byte[] data) throws Exception {
lock.lock();
Transaction t = activeTransaction.get(xid);
lock.unlock();
if(t.err != null) {
throw t.err;
}
byte[] raw = Entry.wrapEntryRaw(xid, data);
return dm.insert(xid, raw);
}raw的数据结构如下
进入dm.insert(xid, raw),与创建表的过程一样
public long insert(long xid, byte[] data) throws Exception {
byte[] raw = DataItem.wrapDataItemRaw(data);
if(raw.length > PageX.MAX_FREE_SPACE) {
throw Error.DataTooLargeException;
}
PageInfo pi = null;
for(int i = 0; i < 5; i ++) {
pi = pIndex.select(raw.length);
if (pi != null) {
break;
} else {
int newPgno = pc.newPage(PageX.initRaw());
pIndex.add(newPgno, PageX.MAX_FREE_SPACE);
}
}
if(pi == null) {
throw Error.DatabaseBusyException;
}
Page pg = null;
int freeSpace = 0;
try {
pg = pc.getPage(pi.pgno);
byte[] log = Recover.insertLog(xid, pg, raw);
logger.log(log);
short offset = PageX.insert(pg, raw);
pg.release();
return Types.addressToUid(pi.pgno, offset);
} finally {
// 将取出的pg重新插入pIndex
if(pg != null) {
pIndex.add(pi.pgno, PageX.getFreeSpace(pg));
} else {
pIndex.add(pi.pgno, freeSpace);
}
}
}log的数据结构如下
logger.log(log)中
public void log(byte[] data) {
byte[] log = wrapLog(data);
ByteBuffer buf = ByteBuffer.wrap(log);
lock.lock();
try {
fc.position(fc.size());
fc.write(buf);
} catch(IOException e) {
Panic.panic(e);
} finally {
lock.unlock();
}
// 添加log后需要对log文件的头部的校验和进行更新
updateXChecksum(log);
}log被进一步被打包成下面的结构
接着将log写入到.log文件中,最后更新整个文件的校验和updateXChecksum(log),之后回到
short offset = PageX.insert(pg, raw);
pg.release();
return Types.addressToUid(pi.pgno, offset);进入short offset = PageX.insert(pg, raw); ,将raw数据写入磁盘中
public static short insert(Page pg, byte[] raw) {
pg.setDirty(true); // 此时该位置数据更新 所以为脏数据
short offset = getFSO(pg.getData()); // 获取空闲位置的偏移 在之后插入数据
System.arraycopy(raw, 0, pg.getData(), offset, raw.length);
setFSO(pg.getData(), (short)(offset + raw.length));
return offset;
}写入 磁盘后将page,放回pageIndex中
finally {
// 将取出的pg重新插入pIndex
if(pg != null) {
pIndex.add(pi.pgno, PageX.getFreeSpace(pg));
} else {
pIndex.add(pi.pgno, freeSpace);
}
}以上是将sql的执行日志保存下来,用于recover,
回到table.insert(xid, insert)中
接下来才是真正写数据的过程
for (Field field : fields) {
if(field.isIndexed()) {
field.insert(entry.get(field.fieldName), uid);
}
}field.insert()向b+树插入数据
public void insert(Object key, long uid) throws Exception {
long uKey = value2Uid(key);
bt.insert(uKey, uid);
}执行完以上步骤回到tbm.insert()
return "insert".getBytes();返回到主函数,执行结束。
9.查询语句执行流程
以下面的的sql语句作为例子
ss="select name,age from students where age=18";
b=ss.getBytes(StandardCharsets.UTF_8);
stat = Parser.Parse(b);
byte[] output=tbm.read(xid,(Select) stat);
进入tbm.read(xid, (Select) stat),同样先查询是否存在该表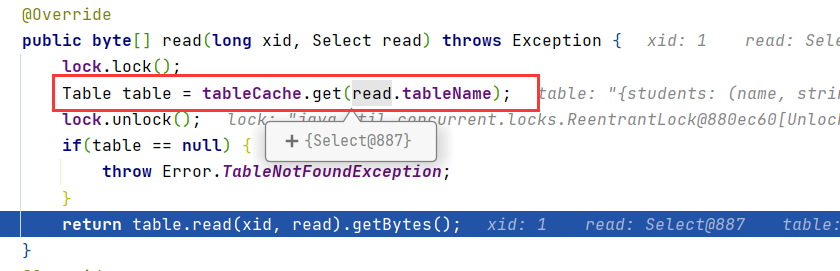
进入table.read(xid, read);
public String read(long xid, Select read) throws Exception {
// 解析where条件并得到需要查询的uid列表
List<Long> uids = parseWhere(read.where);
StringBuilder sb = new StringBuilder();
// 循环遍历uids列表,逐个查询对应的记录,并输出结果
for (Long uid : uids) {
byte[] raw = ((TableManagerImpl)tbm).vm.read(xid, uid);
if(raw == null) continue;
Map<String, Object> entry = parseEntry(raw);
sb.append(printEntry(entry)).append("\n");
}
return sb.toString();
}首先解析where条件中的字段以及数据parseWhere(Where where),这一步主要就是找到where条件查询的字段,交给calWhere(fd, where)查找出条件的上下界,其中逻辑比较简单,不在赘述。
private CalWhereRes calWhere(Field fd, Where where) throws Exception {
CalWhereRes res = new CalWhereRes();
switch(where.logicOp) {
case "": // 单个where条件
res.single = true;
FieldCalRes r = fd.calExp(where.singleExp1);
res.l0 = r.left; res.r0 = r.right;
break;
case "or": // or查询,两次查询结果取并集
res.single = false;
r = fd.calExp(where.singleExp1);
res.l0 = r.left; res.r0 = r.right;
r = fd.calExp(where.singleExp2);
res.l1 = r.left; res.r1 = r.right;
break;
case "and": // and查询 最后两个结果取交集
res.single = true;
r = fd.calExp(where.singleExp1);
res.l0 = r.left; res.r0 = r.right;
r = fd.calExp(where.singleExp2);
res.l1 = r.left; res.r1 = r.right;
if(res.l1 > res.l0) res.l0 = res.l1;
if(res.r1 < res.r0) res.r0 = res.r1;
break;
default:
throw Error.InvalidLogOpException;
}
return res;
}
class CalWhereRes {
long l0, r0, l1, r1;
boolean single;
}在calWhere(fd, where)中,会使用fd.calExp(where.singleExp1),其作用返回一个CalWhereRes类型的结果,其中包含结果的范围。
public FieldCalRes calExp(SingleExpression exp) throws Exception {
Object v = null;
FieldCalRes res = new FieldCalRes();
switch(exp.compareOp) {
case "<":
res.left = 0;
v = string2Value(exp.value);
res.right = value2Uid(v);
if(res.right > 0) {
res.right --;
}
break;
case "=":
v = string2Value(exp.value);
res.left = value2Uid(v);
res.right = res.left;
break;
case ">":
res.right = Long.MAX_VALUE;
v = string2Value(exp.value);
res.left = value2Uid(v) + 1;
break;
}
return res;
}v = string2Value(exp.value);在insert操作时也会使用
将字段数据转换为数字ukey,便于精准查询和范围查询。所以经过calExp()函数的处理后便能够得到响应的左右边界,再到b+树中查询即可。
此时的函数调用栈如下图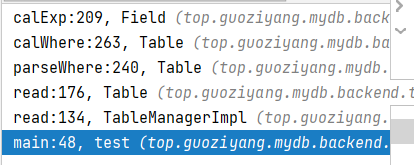
接着回到parseWhere(Where where)函数中
List<Long> uids = fd.search(l0, r0);
if(!single) { // 若为or查询 还要查询l1,r1范围并加入到结果集中 也就是并集
List<Long> tmp = fd.search(l1, r1);
uids.addAll(tmp);
}
return uids;进入feild中查找fd.search()会调用b+tree的searchRange()方法
public List<Long> search(long left, long right) throws Exception {
return bt.searchRange(left, right);
}searchRange()代码逻辑如下
public List<Long> searchRange(long leftKey, long rightKey) throws Exception {
long rootUid = rootUid(); // 获取根节点的UID
long leafUid = searchLeaf(rootUid, leftKey); // 搜索左边界所在的叶子节点
List<Long> uids = new ArrayList<>();
while(true) {
Node leaf = Node.loadNode(this, leafUid); // 加载叶子节点
LeafSearchRangeRes res = leaf.leafSearchRange(leftKey, rightKey); // 在叶子节点中搜索符合条件的数据项
leaf.release(); // 释放叶子节点
uids.addAll(res.uids); // 将符合条件的数据项的UID添加到结果列表中
if(res.siblingUid == 0) { // 如果没有兄弟节点,则说明已经搜完了所有符合条件的数据项
break;
} else {
leafUid = res.siblingUid; // 否则,继续搜索下一个兄弟节点
}
}
return uids;
}经过leaf.leafSearchRange(leftKey, rightKey);便可以得到符合条件的uid
再返回到searchRange()中
while(true) {
Node leaf = Node.loadNode(this, leafUid); // 加载叶子节点
LeafSearchRangeRes res = leaf.leafSearchRange(leftKey, rightKey); // 在叶子节点中搜索符合条件的数据项
leaf.release(); // 释放叶子节点
uids.addAll(res.uids); // 将符合条件的数据项的UID添加到结果列表中
if(res.siblingUid == 0) { // 如果没有兄弟节点,则说明已经搜完了所有符合条件的数据项
break;
} else {
leafUid = res.siblingUid; // 否则,继续搜索下一个兄弟节点
}
}
return uids;释放叶子节点,将满足条件的uid加入到集合,返回给feild.search(),再返回到table.search(),此时回到table.read(xid, read)中
// 执行完的代码注释了
public String read(long xid, Select read) throws Exception {
// 解析where条件并得到需要查询的uid列表
//List<Long> uids = parseWhere(read.where);
StringBuilder sb = new StringBuilder();
// 循环遍历uids列表,逐个查询对应的记录,并输出结果
for (Long uid : uids) {
byte[] raw = ((TableManagerImpl)tbm).vm.read(xid, uid);
if(raw == null) continue;
Map<String, Object> entry = parseEntry(raw);
sb.append(printEntry(entry)).append("\n");
}
return sb.toString();
}接下来遍历uids列表,交给vm模块,读取uid。vm.read(xid, uid)代码如下,VM继承了计数缓存框架,会先到缓存中查找数据,也就是entry = super.get(uid);这行代码。
public byte[] read(long xid, long uid) throws Exception {
lock.lock();
Transaction t = activeTransaction.get(xid);
lock.unlock();
if(t.err != null) {
throw t.err;
}
Entry entry = null;
try {
entry = super.get(uid); // VM继承了计数缓存框架,会先到缓存中查找数据
} catch(Exception e) {
if(e == Error.NullEntryException) {
return null;
} else {
throw e;
}
}
try {
if(Visibility.isVisible(tm, t, entry)) {
return entry.data();
} else {
return null;
}
} finally {
entry.release();
}
}接下来进入AbstractCache.get(),代码很长。
protected T get(long key) throws Exception {
while(true) {
lock.lock();
if(getting.containsKey(key)) { // getting为正在获取某资源的线程
// 请求的资源正在被其他线程获取
lock.unlock();
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
continue;
}
continue;
}
if(cache.containsKey(key)) {
// 资源在缓存中,直接返回
T obj = cache.get(key);
// 将事务xid加入到引用了该uid的列表中
references.put(key, references.get(key) + 1);
lock.unlock();
return obj;
}
// 尝试获取该资源 maxResource是缓存的最大缓存资源数
if(maxResource > 0 && count == maxResource) {
lock.unlock();
throw Error.CacheFullException;
}
count ++;
getting.put(key, true);
lock.unlock();
break;
}
T obj = null;
try {
// 资源不在缓存中时
obj = getForCache(key);
} catch(Exception e) {
lock.lock();
count --;
getting.remove(key);
lock.unlock();
throw e;
}
lock.lock();
getting.remove(key);
cache.put(key, obj); // 将从磁盘中加载的
references.put(key, 1);
lock.unlock();
return obj;
}因为是第一次查询所以,肯定不在缓存中,需要到磁盘中查找obj = getForCache(key)
protected Entry getForCache(long uid) throws Exception {
Entry entry = Entry.loadEntry(this, uid);
if(entry == null) {
throw Error.NullEntryException;
}
return entry;
}
public static Entry loadEntry(VersionManager vm, long uid) throws Exception {
DataItem di = ((VersionManagerImpl)vm).dm.read(uid);
return newEntry(vm, di, uid);
}获取到entry后,回到AbstractCache.get()
lock.lock();
getting.remove(key);
cache.put(key, obj); // 将从磁盘中加载的entry放入缓存
references.put(key, 1);
lock.unlock();此时的调用栈如下
继续返回,回到vm.read(xid, uid)中,判断可见性后返回记录。
public byte[] read(long xid, long uid) throws Exception {
... //已执行的代码
try {
if(Visibility.isVisible(tm, t, entry)) {
return entry.data();
} else {
return null;
}
} finally {
entry.release();返回到table.read()中,获取的记录如下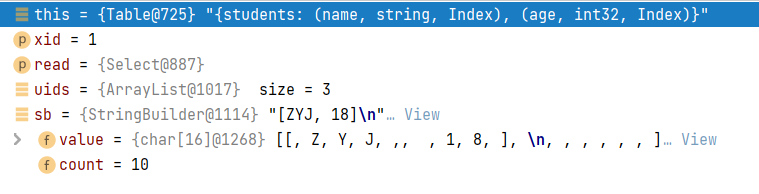
继续向上返回到tbm.read(),继续返回到主函数,控制台打印结果如下
整个过程有亿点点的复杂,真佩服作者
分析隔离级别
读已提交
准备两个测试用例,第一个为创建表后向其中插入一条数据
public static void main(String[] args) {
TransactionManagerImpl tm= TransactionManager.create("cun/tm");
DataManager dm=DataManager.create("cun/dm",1 << 20,tm);
VersionManager vm= VersionManager.newVersionManager(tm,dm);
TableManager tbm=TableManager.create("cun/",vm,dm);
byte[] res;
Executor executor = new Executor(tbm);
String begin = "begin";
byte[] beginBytes = begin.getBytes(StandardCharsets.UTF_8);
String createTB="create table students " +
"name string,age int32 " +
"(index name age)";
byte[] createTBBytes=createTB.getBytes(StandardCharsets.UTF_8);
String insertSQL="insert into students values xiaosun 18";
byte[] insertSQLBytes = insertSQL.getBytes(StandardCharsets.UTF_8);
try {
byte[] bytes = executor.execute(beginBytes);
res = executor.execute(createTBBytes);
System.out.println(new String(res));
executor.execute(insertSQLBytes);
} catch (Exception e) {
e.printStackTrace();
}
}第二测试用例为查询上述插入的数据
public static void main(String[] args) {
TransactionManagerImpl tm= TransactionManager.open("cun/tm");
DataManager dm=DataManager.open("cun/dm",1 << 20,tm);
VersionManager vm= VersionManager.newVersionManager(tm,dm);
TableManager tbm=TableManager.open("cun/",vm,dm);
//开启事务
// BeginRes br=tbm.begin(new Begin());
byte[] res;
Executor executor = new Executor(tbm);
String begin = "begin";
byte[] beginBytes = begin.getBytes(StandardCharsets.UTF_8);
String selectSQL="select name,age from students where age=18";
byte[] selectSQLBytes=selectSQL.getBytes(StandardCharsets.UTF_8);
try {
byte[] bytes = executor.execute(beginBytes);
res = executor.execute(selectSQLBytes);
System.out.println(new String(res));
} catch (Exception e) {
e.printStackTrace();
}
}首先执行test1,执行到byte[] execute = executor.execute(commitSQLBytes);,停止,在test2中查看是否可以查询到该记录
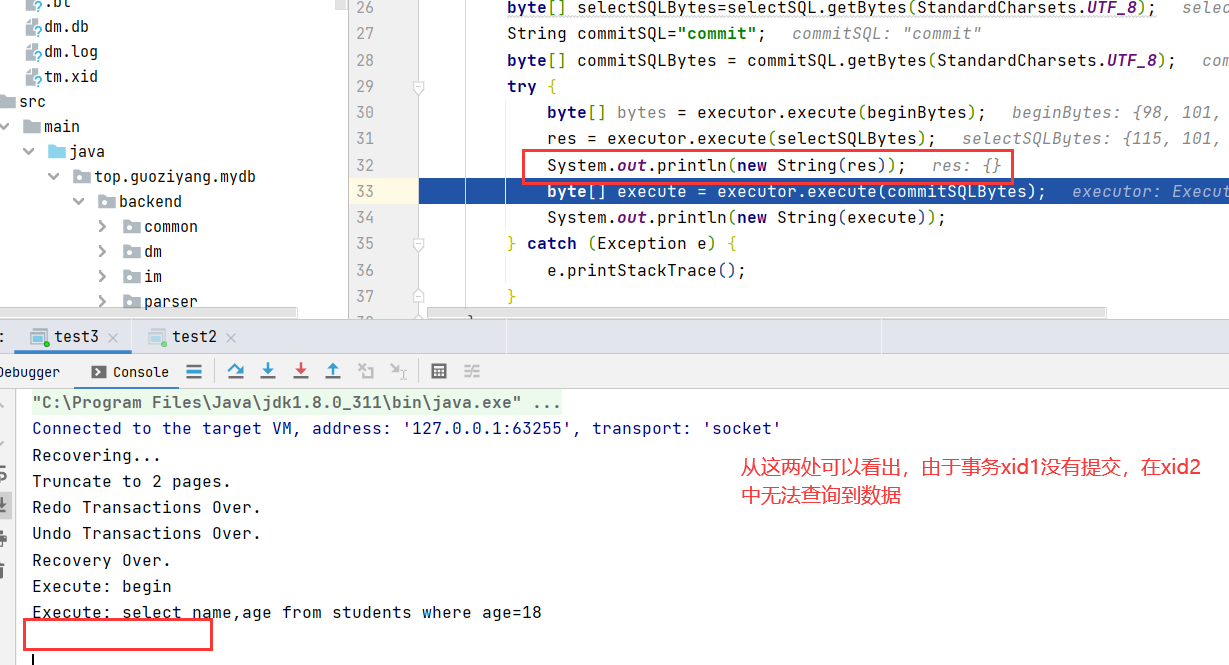
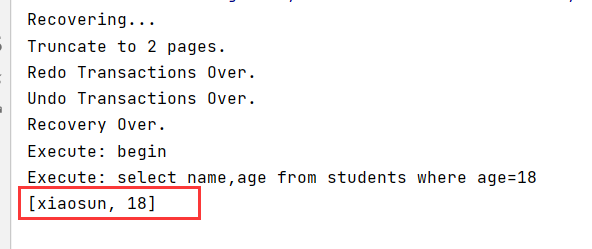
再将test1中的commit语句放行,再次运行test2,可以成功查询到,也就是实现了读已提交的隔离级别
可重复读
参考
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
