商品评价情感分析
本文最后更新于:3 年前
项目综述
对给定的文本进行自动分类,对评价分成好评和差评
支持批量检测,并进行可视化展示
对所有评价进行词云展示
数据获取
爬虫获取JD的商品评价,这里主要针对智能手机的评价
首先是分析如何获取到商品的评价
对商品评价进行提取
对获取的数据进行分类保存
获取评价
首先进行搜索,比如关键词 为手机
self.startUrl = "https://search.jd.com/Search?keyword=%s&enc=utf-8" % (quote('手机')) # jD起始搜索页面之后获取商品的ID,可以在网页源码中提取//li[@class="gl-item"]/@data-sku,具体的节点信息如下

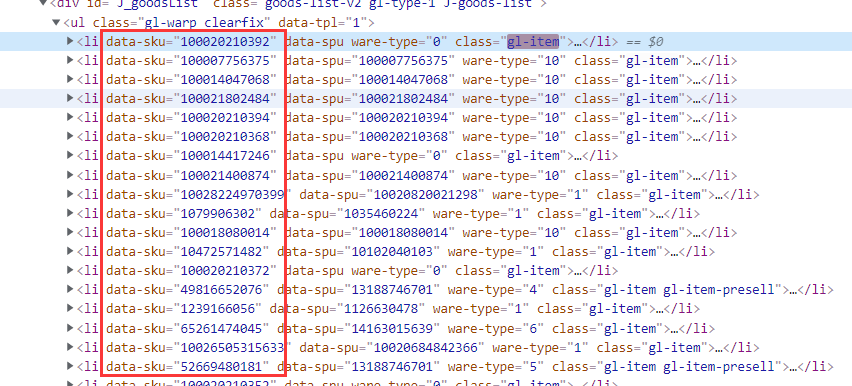
获得商品ID后可以利用JD提供的评价API获取评论页面,如图
api接口如下
https://sclub.jd.com/comment/productPageComments.action?productId=100020210392&score=3&sortType=5&page=2&pageSize=10&isShadowSku=0&rid=0&fold=1其中需要改变的参数为
productId 商品ID
score 评论的分类 1为差评 2为中评 3为好评
page 评论的页数
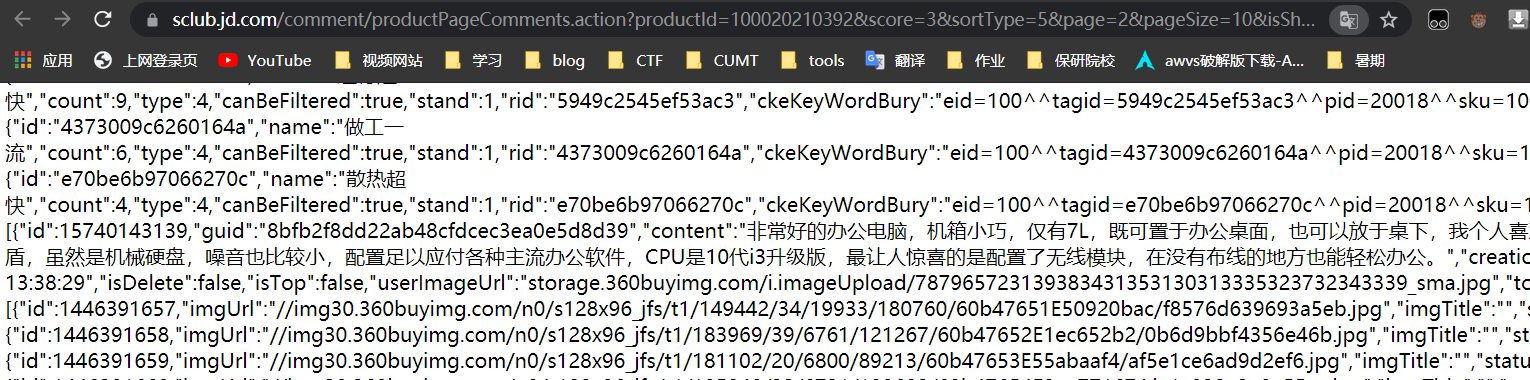
获取这个页面后就是对数据进行提取
数据提取
这里为了方便,先将提取到的数据保存在csv文件中,之后再写入到数据库中
上图中我们需要提取的数据只有评价部分的内容和打分数,也就是,content和socore的数据
这里可以将网页数据转换成json数据后提取,很方便
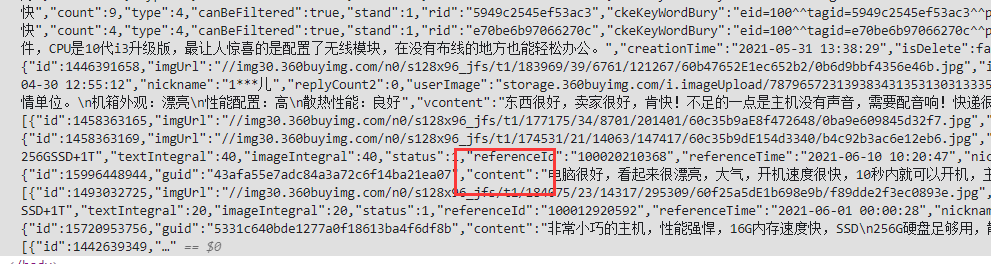
res_json = json.loads(response.text)
for cdit in res_json['comments']:
# comment = cdit['content '].replace("\n", ' ')
comment = cdit['content'].replace("\n", ' ').replace('\r', ' ')
comments.append(comment)
scores.append(cdit['score'])
print(comment)数据保存
savepath = './' + self.categlory + '_' + self.comtype[score] + '.csv'
logging.warning("已爬取%d 条 %s 评价信息" % (len(comments), self.comtype[score]))
with open(savepath, 'a+', encoding='utf8') as f:
for i in range(len(comments)):
f.write("%d\t%s\t%s\n" % (i, scores[i], comments[i]))
logging.warning("数据已保存在 %s" % (savepath))贝叶斯分类
1.加载语料,打乱语料顺序,将语料分为评论和好评/差评
2.去除评论中的英文、停用词
3.将全部语料按1:4分为测试集与训练集
4.使用CountVectorize构造词袋模型
5.使用TfidfTransformer计算tf-idf值作为特征 6.选择多个分类器进行分类(也可以只用一个,这里只用了多项式)
7.选择合适的模型并保存
加载语料
def load_corpus(file_path_pos,file_path_nag):
with open(file_path_pos, 'r',encoding='UTF-8') as f:
reader = csv.reader(f)
rows = [row for row in reader]
with open(file_path_nag, 'r',encoding='UTF-8') as f:
reader = csv.reader(f)
rows_2 = [row for row in reader]
rows.extend(rows_2)
# 将读取出来的语料转为list
review_data = np.array(rows).tolist()
# 打乱语料的顺序
random.shuffle(review_data)
review_list = []
sentiment_list = []
# 第一列为差评/好评, 第二列为评论
for words in review_data:
review_list.append(words[0].split("\t")[2])
if(words[0].split("\t")[1][0] == '5'):
sentiment_list.append(1)
else:
sentiment_list.append(0)
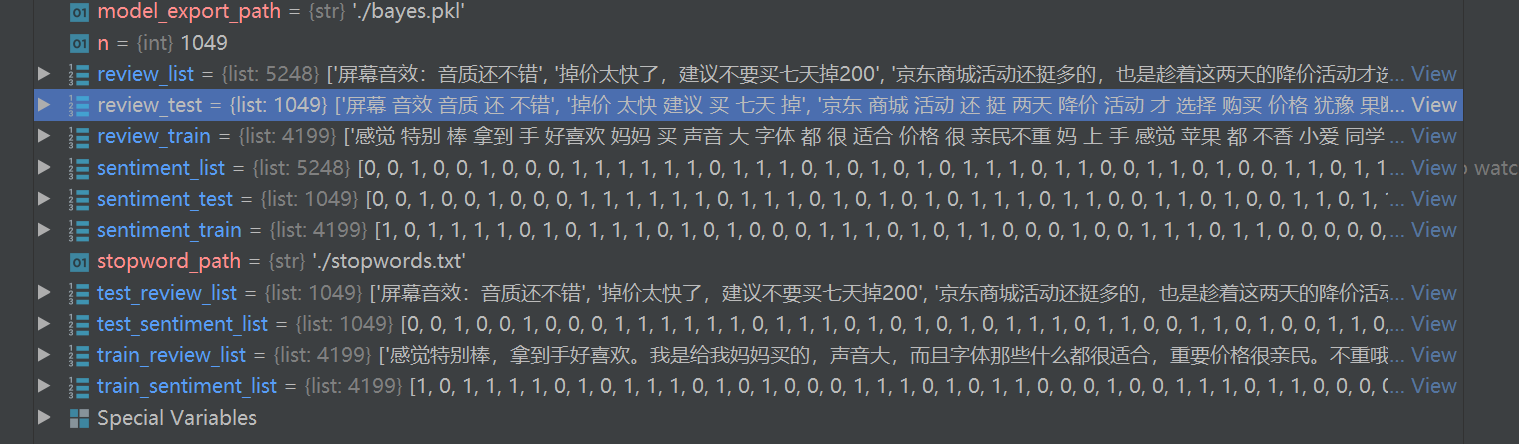
return review_list, sentiment_list生成的数据如下
去除评论中的英文、停用词
这一步的目的是方便后面的词频统计
def load_stopwords(file_path): # 加载停顿词
stop_words = []
with open(file_path, encoding='UTF-8') as words:
stop_words.extend([i.strip() for i in words.readlines()])
return stop_words
def review_to_text(review):
stop_words = load_stopwords(stopword_path)
# 去除英文
review = re.sub("[^\u4e00-\u9fa5^a-z^A-Z]", '', review)
# print(review)
review = jieba.cut(review)
# 去掉停用词,将句子划分成一个个的单词 例如:['赞赞赞', '不错', '很漂亮', '外壳']
words = []
if stop_words:
all_stop_words = set(stop_words)
words = [w for w in review if w not in all_stop_words]
print(words[:4])
return words最后经过处理
review_train = [' '.join(review_to_text(review)) for review in train_review_list]
review_test = [' '.join(review_to_text(review)) for review in test_review_list]呈现如下的效果

训练模型
# 加载语料
review_list, sentiment_list = load_corpus(file_path_pos,file_path_nag)
# 将全部语料按1:4分为测试集与训练集
n = len(review_list) // 5
train_review_list, train_sentiment_list = review_list[n:], sentiment_list[n:]
test_review_list, test_sentiment_list = review_list[:n], sentiment_list[:n]
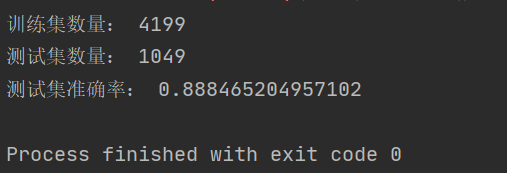
print('训练集数量: {}'.format(str(len(train_review_list))))
print('测试集数量: {}'.format(str(len(test_review_list))))
# 用于训练的评论
review_train = [' '.join(review_to_text(review)) for review in train_review_list] # 将句子中的单词重新拼接,形成无停顿词的句子
# 对于训练评论对应的好评/差评
sentiment_train = train_sentiment_list
# 用于测试的评论
review_test = [' '.join(review_to_text(review)) for review in test_review_list]
print(review_test[:3])
# 对于测试评论对应的好评/差评
sentiment_test = test_sentiment_list
vectorizer = CountVectorizer(max_df=0.8, min_df=3)
tfidftransformer = TfidfTransformer()
# 先转换成词频矩阵,再计算TFIDF值
tfidf = tfidftransformer.fit_transform(vectorizer.fit_transform(review_train))
# 朴素贝叶斯中的多项式分类器,训练模型
clf = MultinomialNB().fit(tfidf, sentiment_train)
# 将模型保存pickle文件
with open(model_export_path, 'wb') as file:
d = {
"clf": clf,
"vectorizer": vectorizer,
"tfidftransformer": tfidftransformer,
}
pickle.dump(d, file)
print("训练完成")使用测试数据集验证该模型的准确性
count_vec = CountVectorizer(max_df=0.8, min_df=3)
tfidf_vec = TfidfTransformer()
# 定义Pipeline对全部步骤的流式化封装和管理,可以很方便地使参数集在新数据集(比如测试集)上被重复使用。
def MNB_Classifier():
return Pipeline([
('count_vec', count_vec),
('tfidf_vec', tfidf_vec),
('mnb', MultinomialNB())
])
mnbc_clf = MNB_Classifier()
# 进行训练
mnbc_clf.fit(review_train, sentiment_train)
# 测试集准确率
print('测试集准确率: {}'.format(mnbc_clf.score(review_test, sentiment_test)))准确性可以达到88%,是一个不错的结果
可视化网页
数据库
将爬取的评论写入数据库,将网页中输入的检测数据和结果写入数据库,以及用户登录账号密码
所以需要三个数据表保存上面提到的三种数据
这里使用脚本一键完成
# -*- coding = utf - 8 -*-
#@Time : 2021/8/6 22:35
#@Author : sunzy
#@File : db_helper.py
import re
import csv
import random
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', password='root', port=3306, db='goods',
charset='utf8mb4')
def createTable():
sql = "create table comment(id int primary key auto_increment,comment varchar(800) CHARACTER SET 'utf8',type varchar(200) CHARACTER SET 'utf8')"
cur = conn.cursor()
cur.execute(sql)
cur.close()
def createTable1():
sql = "create table user(id int primary key auto_increment,username varchar(80),password varchar(200))"
cur = conn.cursor()
cur.execute(sql)
cur.close()
def createTable2():
sql = "create table result(id int primary key auto_increment,comment varchar(800) CHARACTER SET 'utf8',type varchar(200) CHARACTER SET 'utf8')"
cur = conn.cursor()
cur.execute(sql)
cur.close()
createTable()
createTable1()
createTable2()
with open('手机_nagetive.csv', 'r', encoding='UTF-8') as f:
reader = csv.reader(f)
for row in reader:
r = ''.join(row)
cursor = conn.cursor()
cursor.execute("insert into `comment` values(null, %s, '差评')",
(r.split()[2]));
conn.commit()
cursor.close()
with open('手机_positive.csv', 'r', encoding='UTF-8') as f:
reader = csv.reader(f)
for row in reader:
r = ''.join(row)
cursor = conn.cursor()
cursor.execute("insert into `comment` values(null, %s, '好评')",
(r.split()[2]));
conn.commit()
cursor.close()用户注册和登录
用户的注册和登录逻辑很简单,就是与数据库进行交互
@app.route('/addUser',methods=['POST'])
def addUser():
get_json = request.get_json()
name = get_json['name']
password = get_json['password']
conn = pymysql.connect(host='127.0.0.1', user='root', password='root', port=3306, db='goods',
charset='utf8mb4')
cursor = conn.cursor()
sql = "insert into `user` values(null,'"+name+"','"+password+"','user')"
cursor.execute(sql);
conn.commit()
table_result = {"code": 200, "msg": "成功"}
cursor.close()
conn.close()
return jsonify(table_result)
@app.route('/loginByPassword',methods=['POST'])
def loginByPassword():
get_json = request.get_json()
name = get_json['name']
password = get_json['password']
conn = pymysql.connect(host='127.0.0.1', user='root', password='root', port=3306, db='goods',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `user` where `username` = '" + name +"' and password = '" + password+"'");
count = cursor.fetchall()
if(count[0][0] != 0):
table_result = {"code": 200, "msg": name}
else:
table_result = {"code": 500, "msg": "失败"}
cursor.close()
conn.close()
return jsonify(table_result)用户成功登录后,js脚本会重定向到index.html页面,进入系统主页
form.on('submit(login-submit)', function (obj) {
$.ajax({
type: "post",
contentType: 'application/json',
url: "http://127.0.0.1:5000/loginByPassword",
data: JSON.stringify(obj.field),
dataType: 'json',
success: function (data) {
if (data.code == '200') {
layer.msg('登录成功',
{
icon: 1,
time: 1500
}, function () {
location.replace('../../index.html') //重定向到index.html
})
} else {
layer.alert(data.msg, {icon: 2}, function (index) {
layer.close(index);
});
}
}
})
return false;
});词云展示
使用echarts生成词云
@app.route('/top',methods=['GET'])
def top():
jsondata = {}
if(len(request.args)!=0):
if(request.args['category']=='good'):
jsondata['data'] = good_datas
else:
jsondata['data'] = bad_datas
else:
jsondata['data'] = all_datas
j = jsonify(jsondata)
print(j)
return j数据获取
cursor.execute("select comment from `comment`");
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['comment'])
content = ''.join(data_dict)
all_datas = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
all_datas.append(mydict)
cursor.close()js脚本
function init() {
form.render();
$.ajax({
type: 'GET',
url: 'http://127.0.0.1:5000/top',
beforeSend: function(XMLHttpRequest) {
//注意,layer.msg默认3秒自动关闭,如果数据加载耗时比较长,需要设置time
loadingFlag = layer.msg('正在读取数据,请稍候……', {
icon: 16,
shade: 0.01,
shadeClose: false,
time: 60000
});
},
success: function(res) {
console.log('初始化')
layer.close(loadingFlag);
myCharts2.setOption({
tooltip: {
show: true
},
series: [{
type: "wordCloud",
gridSize: 6,
shape: 'diamond',
sizeRange: [12, 50],
width: 800,
height: 500,
textStyle: {
normal: {
color: function() {
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
}
},
emphasis: {
shadowBlur: 10,
shadowColor: '#333'
}
},
data: res.data,
}]
});
评论检测
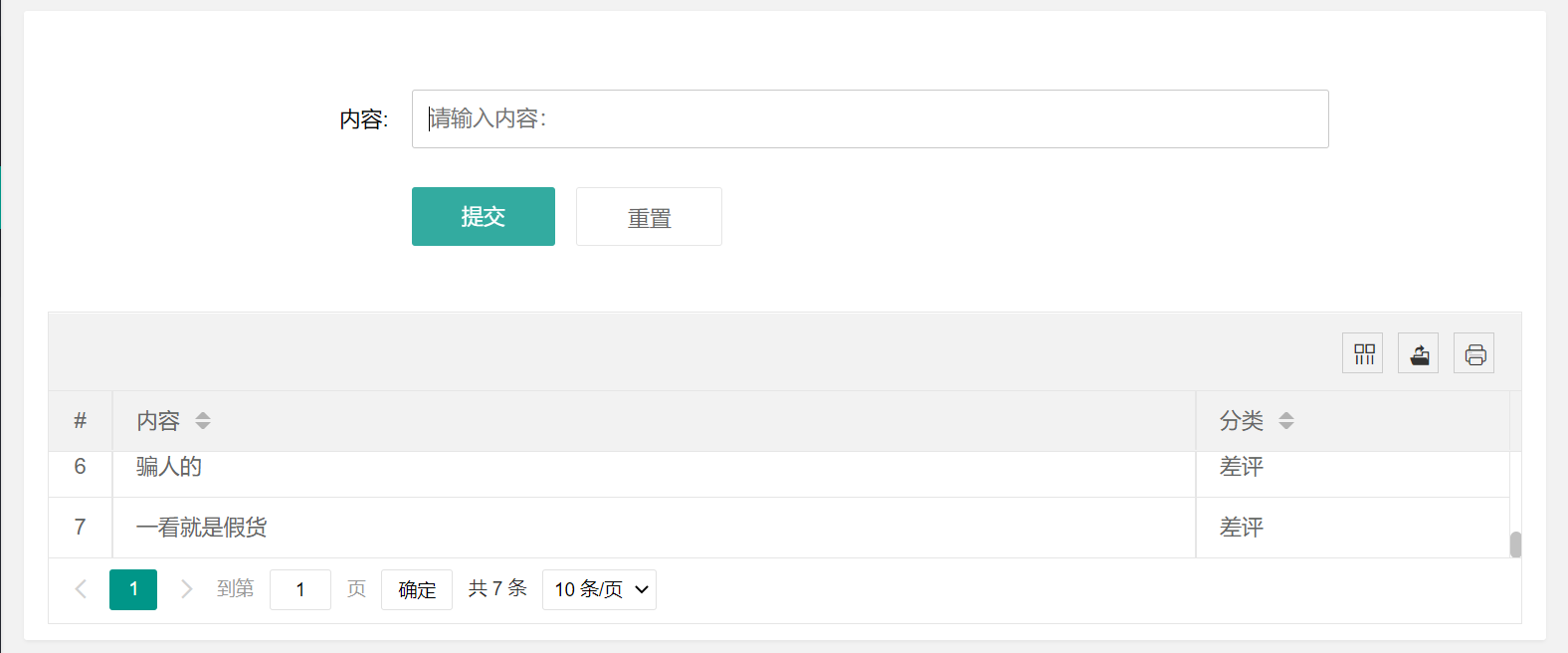
当用户输入检测文本,系统会调用训练好的模型对文本进行情感分析,并将得到的结果写入数据库,之后在页面中显示
python代码
@app.route('/data1',methods=['GET'])
def data1():
path = str(request.args['path'])
data = []
if(len(path)==0):
table_result = {"code": 0, "msg": None, "count": 0, "data": data}
else:
with open(path, 'r', encoding='UTF-8') as f:
reader = f.readlines()
rows = [row for row in reader]
for i in rows:
result = analyzer.analyze(i) // 调用已经封装好的模型对提交的文本进行检测,返回结果
d = {"content":i,"result":result}
data.append(d)
table_result = {"code": 0, "msg": None, "count": 10, "data": data}
return jsonify(table_result)
@app.route('/ksh',methods=['GET'])
def ksh():
path = str(request.args['path'])
good = 0
bad = 0
if(len(path)==0):
table_result = {"code": 0, "msg": None, "count": 0, "data": data}
else:
with open(path, 'r', encoding='UTF-8') as f:
reader = f.readlines()
rows = [row for row in reader]
for i in rows:
result = analyzer.analyze(i)
if(result == "好评"):
good+=1
else:
bad+=1
table_result = {"good": good, "bad": bad}
return jsonify(table_result)
js脚本
var insTb = table.render({
elem: '#tableUser',
url: 'http://127.0.0.1:5000/data',
height: 'full-250',
page: true,
toolbar: true,
cellMinWidth: 100,
cols: [
[{
type: 'numbers',
title: '#'
},
{
field: 'content',
sort: true,
title: '内容'
},
{
field: 'type',
sort: true,
title: '分类',
width:200,
templet: function(d){
if(d.TYPE == 1){
return '好评'
}else{
return '差评'
}
}
}
]
]
});
批量检测
批量检测是将多条评论写入txt文件中,实现一次检测多条评论,然后将数据显示在页面中,并呈现可视化结果
@app.route('/data',methods=['GET'])
def data():
limit = int(request.args['limit'])
page = int(request.args['page'])
page = (page-1)*limit
conn = pymysql.connect(host='127.0.0.1', user='root', password='root', port=3306, db='goods',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `result`");
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from `result` limit "+str(page)+","+str(limit));
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
table_result = {"code": 0, "msg": None, "count": count[0], "data": data_dict}
cursor.close()
conn.close()
return jsonify(table_result)js脚本
upload.render({ //允许上传的文件后缀
elem: '#test_upload',
url: 'http://127.0.0.1:5000/upload',
field: 'myfile',
accept: 'file', //普通文件
exts: 'txt', //只允许上传txt文件
before: function(obj) { //obj参数包含的信息,跟 choose回调完全一致,可参见上文。
layer.load(); //上传loading
},
done: function(res) {
layer.closeAll('loading');
layer.msg('上传成功');
console.log(res)
path = res.path
insTb.reload({
where: {
'path': path
}
});
$.ajax({
type: 'GET',
url: 'http://127.0.0.1:5000/ksh',
data: {
'path': path
},
success: function(result) {
var option = {
tooltip: {
trigger: 'item',
formatter: '{a} <br/>{b} : {c} ({d}%)'
},
legend: {
orient: 'vertical',
left: 'left',
data: ['有效评论', '垃圾评论']
},
series: [{
name: '评论比例',
type: 'pie',
radius: '55%',
center: ['50%', '60%'],
data: [{
value: result.good,
name: '有效评论'
},
{
value: result.bad,
name: '垃圾评论'
}
],
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}]
};
myCharts.setOption(option)
}
});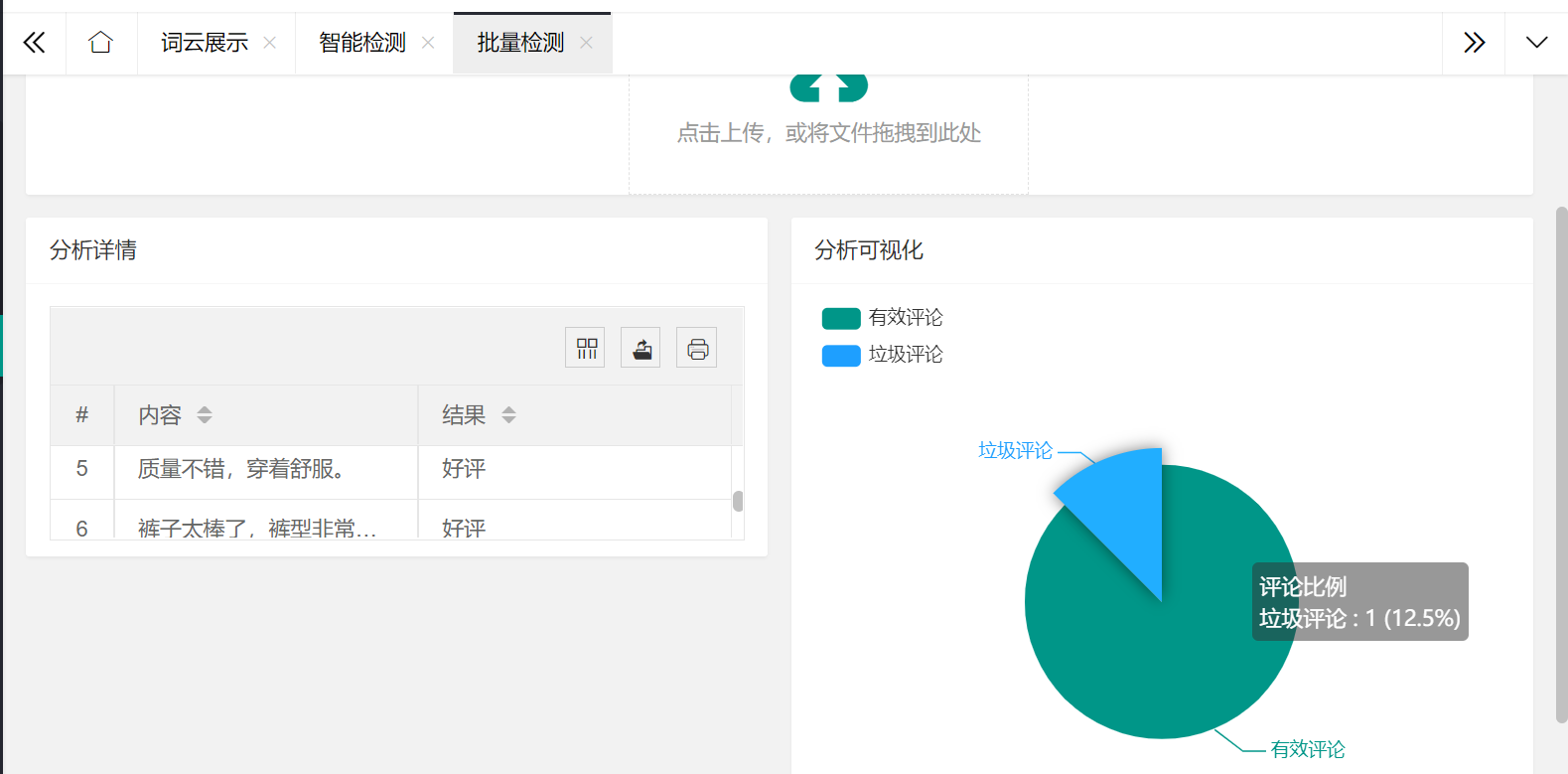
最后呈现的效果
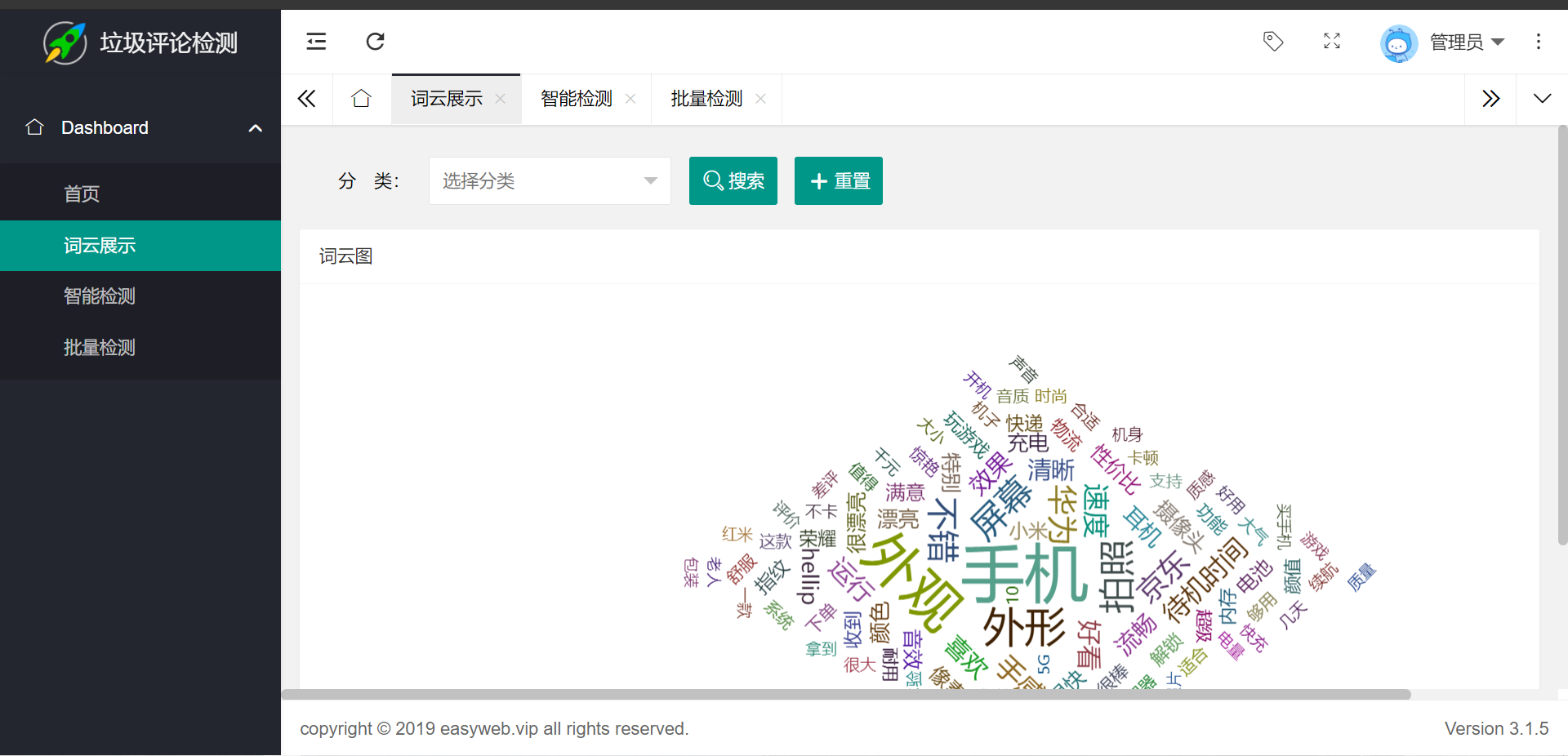
参考:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
