spiderofwords
本文最后更新于:1 年前
scripy爬虫爬取单词(word.iciba.com)
scripy爬虫爬取单词X
首先创建一个有关数据库操作的py
dbhelper.py
import pymysql
from scrapy.utils.project import get_project_settings
// MYSQL_HOST等参数定义在setting.py中
// 也可以直接定义在这个文件中
class DBHelper():
def __init__(self):
self.settings = get_project_settings()
self.host = self.settings['MYSQL_HOST']
self.port = self.settings['MYSQL_PORT']
self.user = self.settings['MYSQL_USER']
self.passwd = self.settings['MYSQL_PASSWD']
self.db = self.settings['MYSQL_DBNAME']
// 建立数据库连接
def connectMysql(self):
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
charset='utf8')
return conn
// 创建数据库
def connectDatabase(self):
conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset='utf8')
return conn
# 创建要使用到的数据库
def createDatabase(self):
conn = self.connectMysql()
sql = "create database if not exists " + self.db
cur = conn.cursor()
cur.execute(sql) #
cur.close()
conn.close()
# 创建数据表
def createTable(self, sql):
conn = self.connectDatabase()
cur = conn.cursor()
cur.execute(sql)
cur.close()
conn.close()
# 向数据库中插入数据
def insert(self, sql, *params): #
conn = self.connectDatabase()
cur = conn.cursor();
cur.execute(sql, params)
conn.commit()
cur.close()
conn.close()
# 数据库更新操作
def update(self, sql, *params):
conn = self.connectDatabase()
cur = conn.cursor()
cur.execute(sql, params)
conn.commit()
cur.close()
conn.close()
def delete(self, sql, *params):
conn = self.connectDatabase()
cur = conn.cursor()
cur.execute(sql, params)
conn.commit()
cur.close()
conn.close()
class TestDBHelper():
def __init__(self):
self.dbHelper = DBHelper()
def testCreateDatebase(self):
self.dbHelper.createDatabase()
def testCreateTable(self):
sql = "create table wordtable(id int primary key auto_increment,word varchar(50),soundmark varchar(100),url varchar(200),translation varchar(100))"
self.dbHelper.createTable(sql)
def testInsert(self):
sql = "insert into wordtable(word,soundmark,url,translation) values(%s,%s,%s,%s)"
params = ("test", "test", "test", "test")
self.dbHelper.insert(sql, *params)
def testUpdate(self):
sql = "update testtable set word=%s,soundmark=%s,url=%s,translation=%s where id=%s"
params = ("update", "update", "update", "update","1")
self.dbHelper.update(sql, *params)
def testDelete(self):
sql = "delete from wordtable where id=%s"
params = ("1")
self.dbHelper.delete(sql, *params)
if __name__ == "__main__":
testDBHelper = TestDBHelper()
# testDBHelper.testCreateDatebase()
# testDBHelper.testCreateTable()
# testDBHelper.testInsert()在编写爬虫之前先运行一次该程序,就可以在数据库中看到新创建的数据库
爬虫编写
setting.py
BOT_NAME = 'words'
SPIDER_MODULES = ['words.spiders']
NEWSPIDER_MODULE = 'words.spiders'
#Mysql数据库的配置信息
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'word' #数据库名字,请修改
MYSQL_USER = 'root' #数据库账号,请修改
MYSQL_PASSWD = 'root' #数据库密码,请修改
MYSQL_PORT = 3306 #数据库端口,在dbhelper中使用
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'word (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36'
LOG_LEVEL = "WARNING"
ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 两个管道的优先级相同
'words.pipelines.WebcrawlerScrapyPipeline': 300, #保存到mysql数据库
'words.pipelines.JsonWithEncodingPipeline': 300, #保存到json文件中
}items.py
import scrapy
class WordsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
word = scrapy.Field()
soundmark = scrapy.Field()
url = scrapy.Field()
translation = scrapy.Field()
web_word.py
爬虫文件
import scrapy
import re
import os
import urllib
import sys
import urllib.request
from scrapy.selector import Selector
from scrapy.http import HtmlResponse,Request
from words.items import WordsItem
class WebWordSpider(scrapy.Spider):
name = 'web_word'
allowed_domains = ['word.iciba.com/']
# class 是四级必备单词,这里可以根据需要选择不同的单词表
first_url = "http://word.iciba.com/?action=words&class=11&course={}"
start_urls = []
# 生成爬取需要的url地址池
# 可以根据需要修改nums,控制爬取的单词数
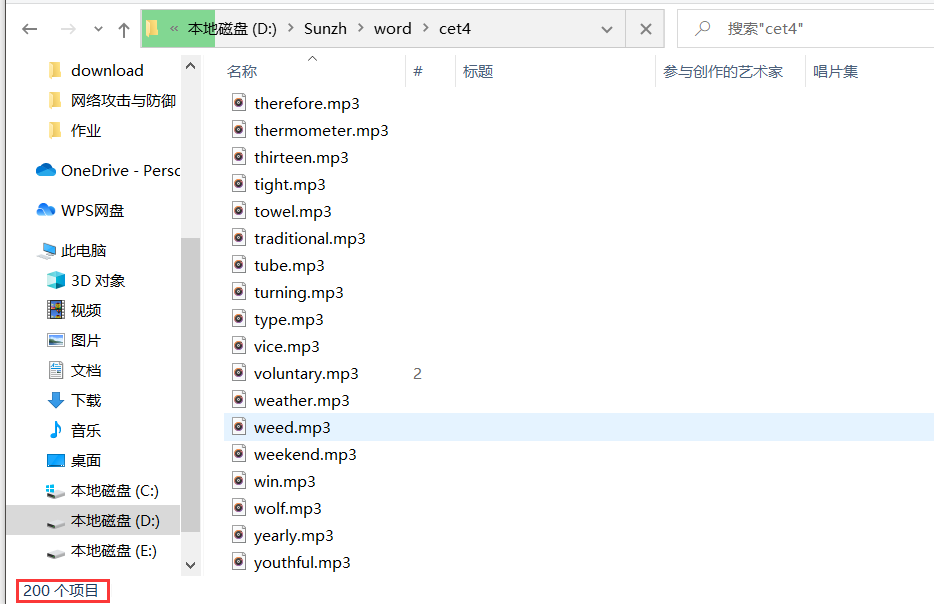
nums = 11 # 爬取前10页的单词,一共200个单词
for page in range(1,nums):
start_urls.append(first_url.format(page))
print(start_urls)
def parse(self, response):
se = Selector(response)
# 先判断页面中是否存在单词
src = se.xpath("//div[@class='word_main']/ul/li")
# 提取出url中的页数
page = re.findall(r"course=\d+", response.url)[0]
print("===" * 10 + "正在爬取第"+page[7:]+"页"+"===" * 10)
if len(src) > 0:
# 将单词的信息提取出来,word是一个数组,存放的是页面中的所有单词
word = se.xpath("//li/div[@class='word_main_list_w']/span/@title" ).extract() # 提取节点信息
soundmark = se.xpath("//li/div[@class='word_main_list_y']/strong/text()" ).extract()
url = se.xpath("//li/div[@class='word_main_list_y']/a/@id" ).extract()
translation = se.xpath("//li/div[@class='word_main_list_s']/span/@title" ).extract()
# 因为上一步提出的音标存在制表符,这里就用正则提取出正确的音标
for i in range(0,len(word)):
sm = re.findall(r"\[.*?\]",soundmark[i])
soundmark[i] = sm[0]
for i in range(0,len(word)):
file_name = u"%s.mp3" % word[i] # 用单词给mp3文件命名
path = os.path.join("D:\Sunzh\word\cet4", file_name) # mp3保存的路径
urllib.request.urlretrieve(url[i], path) # 下载该mp3文件
item = WordsItem()
item['word'] = word[i]
item['soundmark'] = soundmark[i]
item['url'] = url[i]
item['translation'] = translation[i]
# print(item)
# 将item发给管道处理,在管道中写入数据库和josn文件
yield item
这里是使用xpath获取的节点元素,很简单。
可以在浏览器中下载一个插件XPath Helper,辅助写出xpath路径,它可以将所匹配的元素高亮显示,保证程序中的xpath正确性。
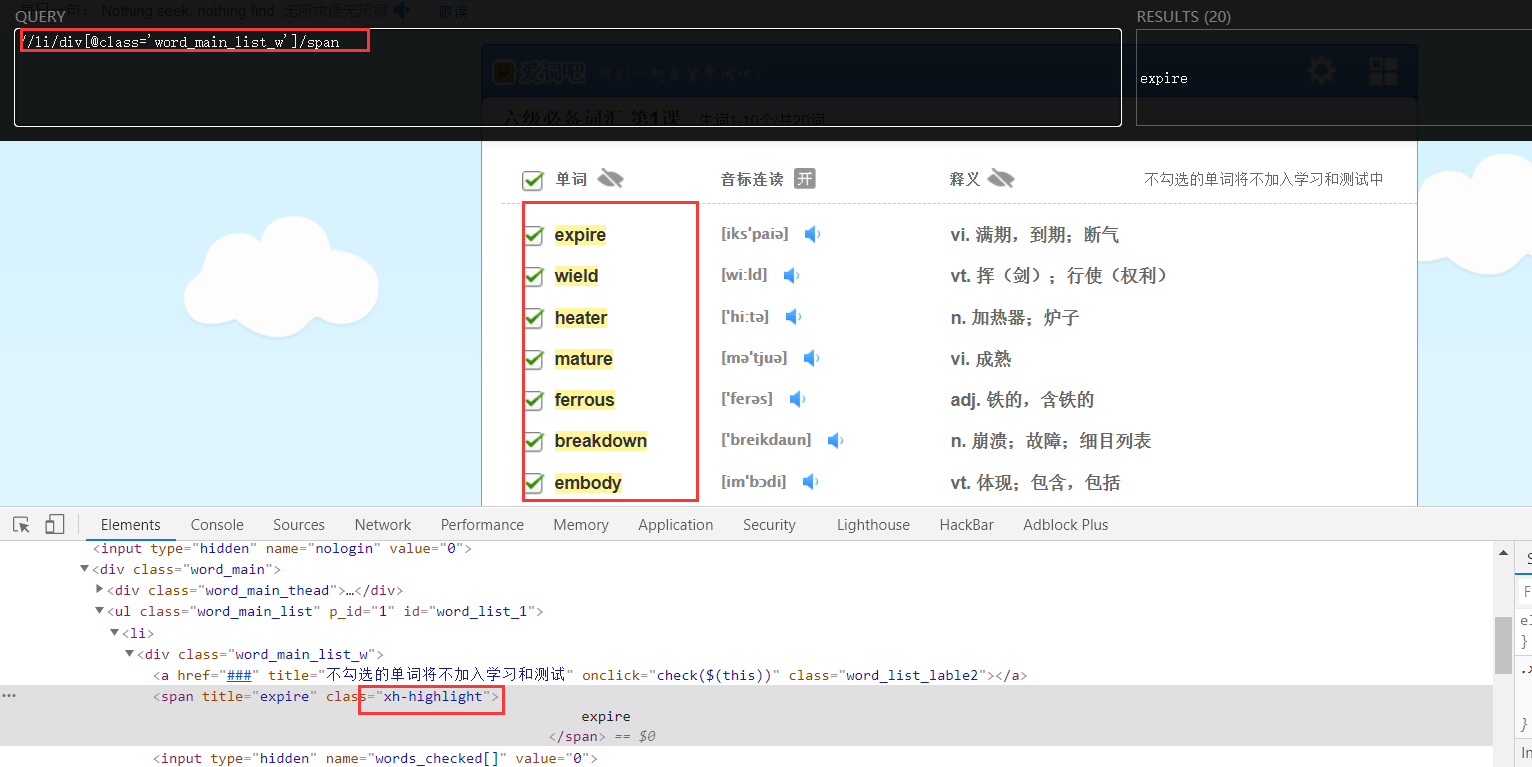
pipelines.py
import pymysql
import pymysql.cursors
import codecs
import json
from logging import log
from twisted.enterprise import adbapi
class JsonWithEncodingPipeline(object):
'''保存到文件中对应的class
1、在settings.py文件中配置
2、在自己实现的爬虫类中yield item,会自动执行
'''
def __init__(self):
self.file = codecs.open('word.json', 'w', encoding='utf-8') # 保存为json文件
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n" # 转为json的
self.file.write(line) # 写入文件中
return item
def spider_closed(self, spider): # 爬虫结束时关闭文件
self.file.close()
class WebcrawlerScrapyPipeline(object):
'''
保存到数据库中对应的class
1、在settings.py文件中配置
2、在自己实现的爬虫类中yield item,会自动执行
'''
def __init__(self, dbpool):
self.dbpool = dbpool # 定义一个数据库连接对象
''' 这里注释中采用写死在代码中的方式连接线程池,可以从settings配置文件中读取,更加灵活
self.dbpool=adbapi.ConnectionPool('MySQLdb',
host='127.0.0.1',
db='crawlpicturesdb',
user='root',
passwd='123456',
cursorclass=MySQLdb.cursors.DictCursor,
charset='utf8',
use_unicode=False)
'''
@classmethod
def from_settings(cls, settings):
'''
1、@classmethod声明一个类方法,而对于平常我们见到的则叫做实例方法。
2、类方法的第一个参数cls(class的缩写,指这个类本身),而实例方法的第一个参数是self,表示该类的一个实例
3、可以通过类来调用,就像C.f(),相当于java中的静态方法
'''
dbparams = dict(
host=settings['MYSQL_HOST'], # 读取settings中的配置
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8', # 编码要加上,否则可能出现中文乱码问题
cursorclass=pymysql.cursors.DictCursor,
use_unicode=False,
)
dbpool = adbapi.ConnectionPool('pymysql', **dbparams) # **表示将字典扩展为关键字参数,相当于host=xxx,db=yyy....
return cls(dbpool) # 相当于dbpool付给了这个类,self中可以得到
# pipeline默认调用
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item) # 调用插入的方法
query.addErrback(self._handle_error, item, spider) # 调用异常处理方法
return item
# 写入数据库中
def _conditional_insert(self, tx, item):
# print (item['word'])
sql = "insert into wordtable(word,soundmark,url,translation) values(%s,%s,%s,%s)"
params = (item["word"], item["soundmark"], item["url"], item["translation"])
tx.execute(sql, params)
# 错误处理方法
def _handle_error(self, failue, item, spider):
print('--------------database operation exception!!-----------------')
print('-------------------------------------------------------------')
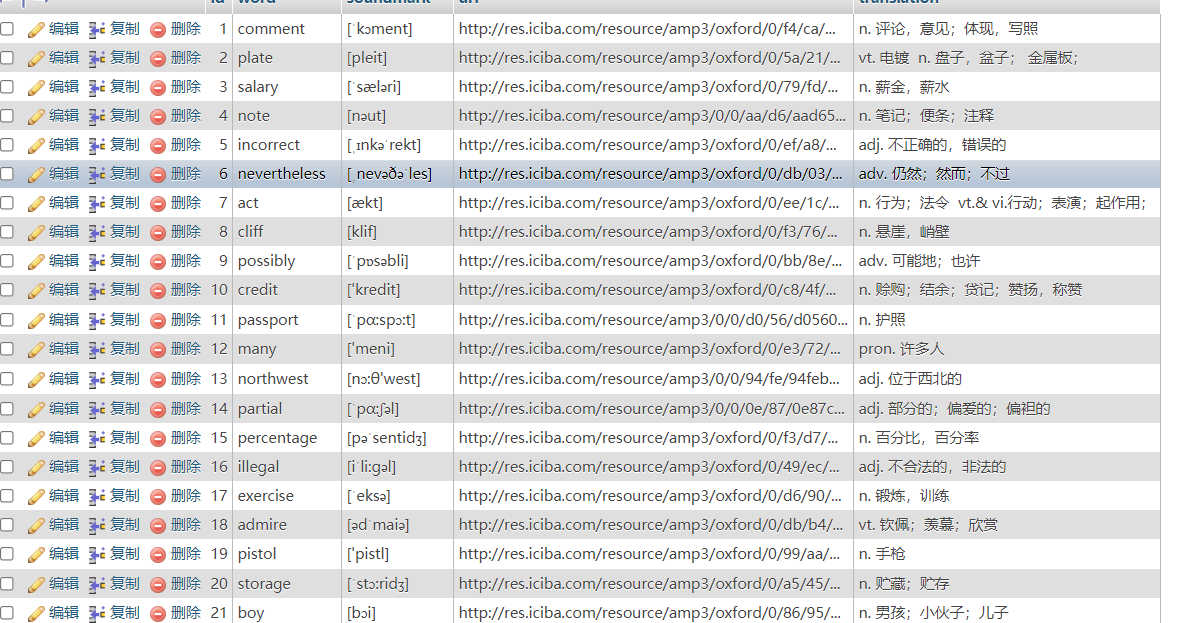
print(failue)pipelines中写了两个方法,分别是将单词的相关性信息写入到数据库,另一个是将单词信息保存到一个json文件中
运行结果
运行截图
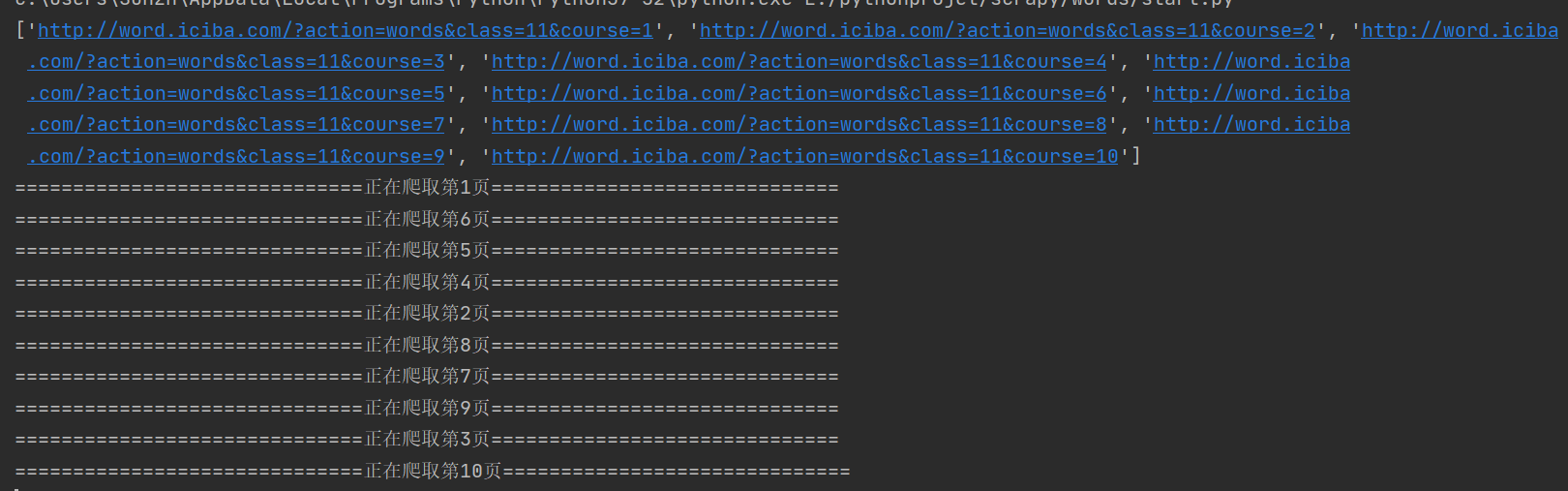
json文件截图

下载的音频
数据库内容
爬取壁纸的爬虫
import scrapy
import pymysql
import re
import os
import urllib
import sys
import urllib.request
from word.items import WordItem
from scrapy.selector import Selector
from scrapy.http import HtmlResponse,Request
class SpiderPicSpider(scrapy.Spider):
name = 'spider_pic'
allowed_domains = ['desk.zol.com.cn'] # 爬虫搜索的域名范围
first_url = "http://desk.zol.com.cn/meinv/1920x1080/{0}.html"
start_urls = [first_url.format(1)] # 爬虫开始的url
def parse(self, response):
for i in range(1, 10):
url = self.first_url.format(i)
yield Request(
url=url,
callback=self.parse_one
)
def parse_one(self, response):
se = Selector(response) # 创建查询对象
if (re.match("https://desk.zol.com.cn/meinv/\d+x\d+/\d+.html", response.url)):
# 正则是判断改url是否正确
src = se.xpath("//ul[@class='pic-list2 clearfix']/li") # 使用xpath找到所有图片所在的节点
for i in range(1, len(src)):
imgURLs = se.xpath("//ul[@class='pic-list2 clearfix']/li[%d]/a/img/@src" % i).extract() # 提取节点信息
title = se.xpath("//ul[@class='pic-list2 clearfix']/li[%d]/a/img/@title" % i).extract()
if imgURLs:
# 替换url中的尺寸信息 可以下载更大的图片
realURL = imgURLs[0].replace("t_s208x130c5", "t_s2560x1600c5")
file_name = u"%s.jpg" % title[0]
path = os.path.join("D:\Sunzh\pic\meinv", file_name) # 拼接图片的路径
type = sys.getfilesystemencoding()
print(file_name.encode(type))
item = WordItem()
item['name'] = file_name
item['url'] = realURL
# print(item['name'],item['url'])
yield item
urllib.request.urlretrieve(realURL, path) # 接收文件路径和需要保存的路径,会自动去文件路径下载并保存到我们指定的本地路径
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
